
1
1
st
lesson Medical students Medical Biology
Molecular Biology
Molecular biology concerns the molecular basis of biological activity between the various
systems of a cell, including the interactions between the different types of
DNA, RNA and proteins and their biosynthesis, and studies how these interactions are
regulated.
Definitions:
Genetics: Study of inherited variations.
Gene: A sequence of DNA that instructs a cell to produce a particular protein.
Allele: Alternate forms of a gene that occurs at a given locus in chromosome.
Plasmid: is small circular DNA molecules which replicates independently of the host
genome and encodes antibiotic resistance are commonest vectors for carrying cloned DNA.
Homozygous: having two identical alleles of a gene (TT or tt).
Heterozygous: having two different alleles of a gene (Tt).
Phenotype: The expression of a gene in traits or symptoms.
Genotype: The alleles combinations in an individual that cause particular traits or disorders.
The genetic code: is the way in which the nucleotide sequence in nucleic acids specifies the
amino acid sequence in proteins. It is a triplet code, where the codons (groups of three
nucleotides) are adjacent. Because many of the 64 codons specify the same amino acids, the
genetic code is degenerate (has redundancy).
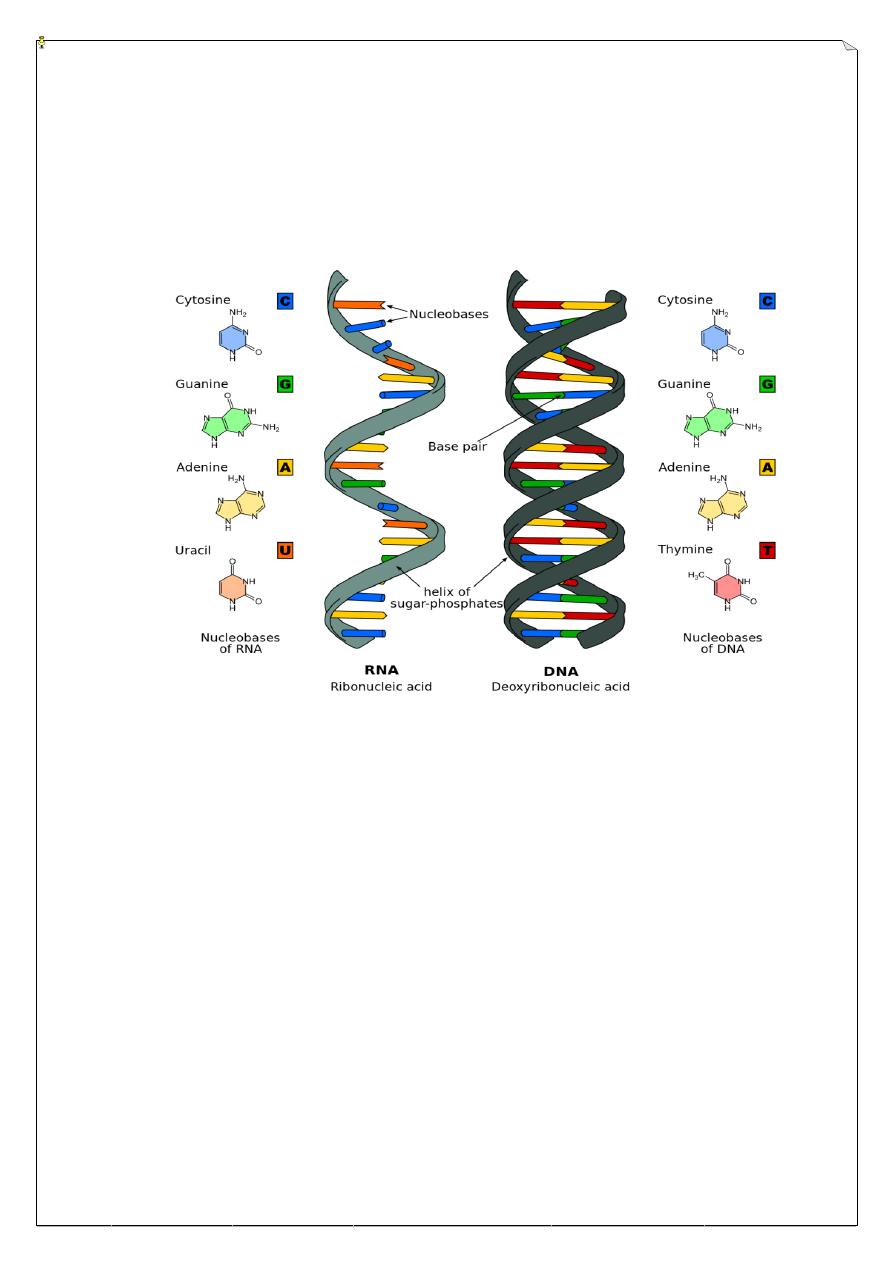
The structure of DNA and RNA
In most organisms, the primary genetic material is double-stranded DNA. Nucleic
acids are heteropolymers composed of monomers known as nucleotides; a nucleic acid
chain is therefore often called a polynucleotide. The monomers are themselves made up of
three components: a sugar, a phosphate group, and a nitrogenous base. The two nucleic
acids are polymers composed of nucleotides; DNA is deoxyribonucleic acid, RNA is
ribonucleic acid. Types of nucleic acid (DNA and RNA) are named according to the sugar
component of the nucleotide, with DNA having 2-deoxyribose as the sugar (hence
DeoxyriboNucleicAcid) and RNA having ribose (hence RiboNucleicAcid). The
2
sugar/phosphate components of a nucleotide are important in determining the structural
characteristics of polynucleotides, and the nitrogenous bases determine their information
storage and transmission characteristics. The nitrogenous bases are the important
components of nucleic acids in terms of their coding function. In DNA the bases are as
listed namely adenine (A), guanine (G), cytosine (C), and thymine (T).
( )لالطالع
In RNA the base thymine is replaced by uracil (U), which is functionally equivalent.
Chemically adenine and guanine are purines, which have a double-ring structure, whereas
cytosine and thymine (and uracil) are pyrimidines, which have a single-ring structure. The
bases are held together by hydrogen bonds, two in the case of an A = T base pair and three
in the case of a G ≡ C base pair. The structure and base-pairing are =arrangement of the four
DNA bases.
RNA is also most commonly single stranded, although short stretches of double-
stranded RNA may be found in self-complementary regions. There are four main types of
RNA molecule found in cells: messenger RNA (mRNA), ribosomal RNA (rRNA),
smallnuclear RNA (snRNA) and transfer RNA (tRNA). Ribosomal RNA is the most
abundant class of RNA molecule, making up some 85% of total cellular RNA. It is
associated with ribosomes, which are an essential part of the translational machinery.

3
Transfer RNAs make up about 10% of total RNA and provide the essential specificity that
enables the insertion of the correct amino acid into the protein that is being synthesized.
Messenger RNA, as the name suggests, acts as the carrier of genetic information from the
DNA to the translational machinery and usually makes up less than 5% of total cellular
RNA.
The anatomy of gene
Although there is no such thing as a ‘typical’ gene, there are certain basic
requirements for any gene to function. The most obvious is that the gene has to encode the
information for the particular protein (or RNA molecule). The double-stranded DNA
molecule has the potential to store genetic information in either strand, although in most
organisms only one strand is used to encode any particular gene. There is the potential for
confusion with the nomenclature of the two DNA strands, which may be called coding/non-
coding, sense/antisense, plus/minus, transcribed/non-transcribed, or template/non-template.
A site for starting transcription is required, and this encompasses a region that binds RNA
polymerase known as the promoter (P), and a specific start point for transcription (TC). A
stop site for transcription (tC) is also required. From TC start to tC stop is sometimes called
the transcriptional unit, that is, the DNA region that is copied into RNA. Within this
transcriptional unit there may be regulatory sites for translation, namely a start site (TL) and
a stop signal (tL). Other sequences involved in the control of gene expression may be
present either upstream or downstream from the gene itself.
Gene structure in prokaryotes
In prokaryotic cells such as bacteria, genes are usually found grouped together in
operons. The operon is a cluster of genes that are (often coding for enzymes in a metabolic

4
pathway) and that are under the control of a single promoter/regulatory region. Perhaps the
best known example of this arrangement is the lac operon (Fig. 2), which encodes for the
enzymes responsible for lactose catabolism. The fact that structural genes in prokaryotes are
often grouped together means that the transcribed mRNA may contain information for more
than one protein. Such a molecule is known as a polycistronic mRNA, with the term
cistron equating to the ‘gene’ as we have defined it (i.e. encoding one protein). Thus, much
of the genetic information in bacteria is expressed via polycistronic mRNAs whose
synthesis is regulated in accordance with the needs of the cell at any given time. This system
is flexible and efficient, and it enables the cell to adapt quickly to changing environmental
conditions.
Gene structure in eukaryotes
A major defining feature of eukaryotic cells is the presence of a membrane-bound
nucleus, within which the DNA is stored in the form of chromosomes. Transcription
therefore occurs within the nucleus and is separated from the site of translation, which is in
the cytoplasm. Gene structure and function in eukaryotes are more complex than in
prokaryotes. Eukaryotic genes contained ‘extra’ pieces of DNA that did not appear in the
mRNA that the gene encoded. These sequences are known as intervening sequences or
introns, with the sequences that will make up the mRNA being called exons.

5
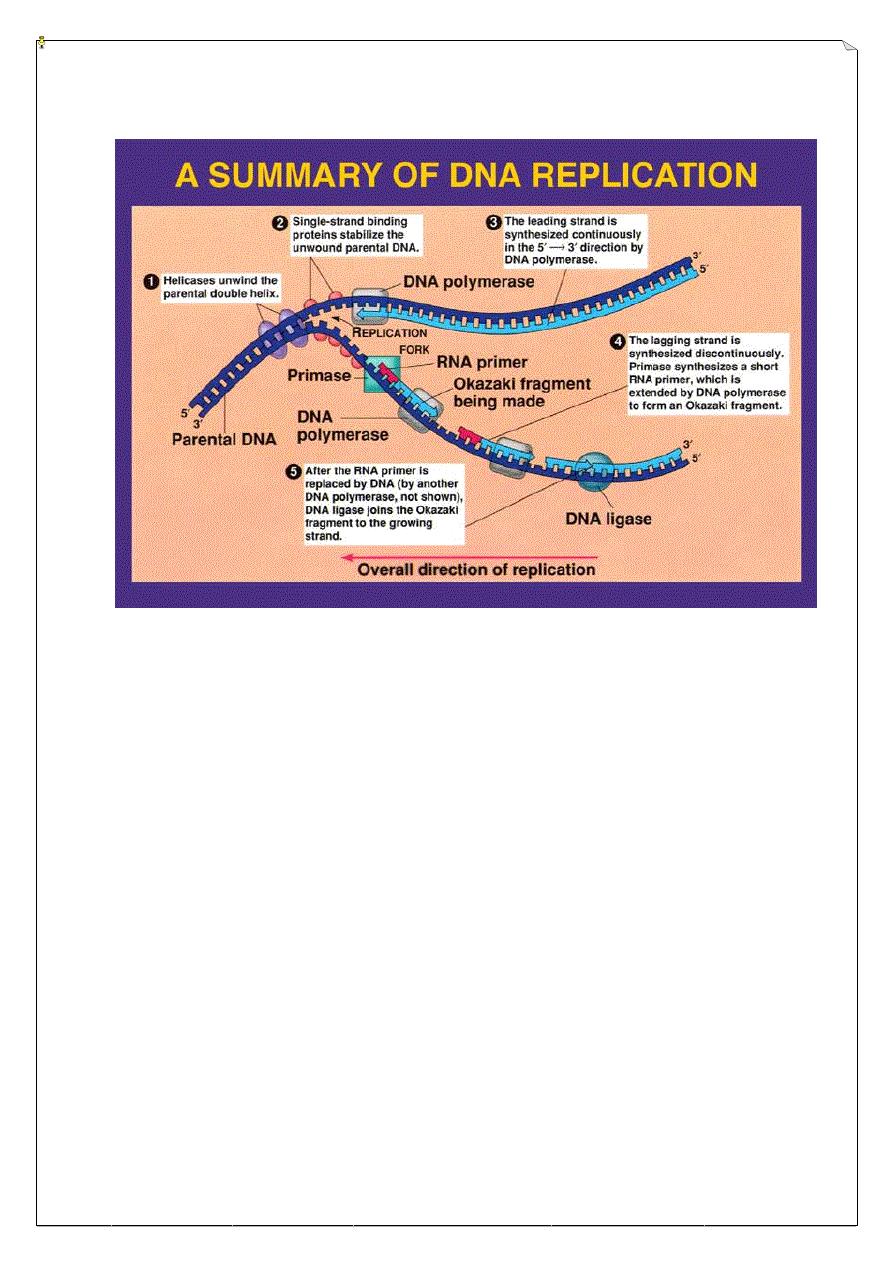
DNA Replication:
•
Replication of DNA is semiconservative .
•
During replication the 2 complementary strands unwind and each single strand
serves as template directing the synthesis of a new complementary strand.
•
The new result of replication is thus 2 progeny DNA molecules identical to the
parental double helix. A site where DNA is locally opened called replication fork.
Enzymes involved in DNA replication and their function:
1.
Helicase: unwinds parental double helix.
2.
Binding Proteins: stabilize separate strands.
3.
Primase: adds short RNA Primer to template strand .
4.
DNA Polymerase :
Adding bases to the new DNA chain, added Bases in (5'→3') direction only and
DNA is antiparallel, the new strand is synthesized continuously in (5'→3') direction called
Leading strand, while the other daughter strand is synthesized discontinuously by short
segments of DNA called Okazaki Fragments (5'→3') that are joined together by ligase and
called Lagging strand.
Proofreading activity checks and replaces incorrect bases.
Removing RNA primer.
5.
Ligase: joins Okazaki fragments and seals other nicks in sugar phosphate
backbone.
Electron micrograph of a eukaryote replicating fork demonstrating the presence of histone-
protein containing nucleosomes on both branches. ( )لالطالع
6
Genome:
A genome is an organism's complete set of deoxyribonucleic acid (DNA), a
chemical compound that contains the genetic instructions needed to develop and direct the
activities of every organism. The human genome contains approximately 3.2 billion of base
pairs, which reside in the 23 pairs of chromosomes (22 autosome pairs + 2 sex
chromosomes) in the haploid genome. Human genome comprise of around 30,000 - 40,000
genes. Only about 3% of human genome encodes for proteins while 40-50% is repetitive
DNA and others are unknown function.
UP By Fahad A.