
Hussien Mohammed Jumaah
CABMLecturer in internal medicine
Mosul College of Medicine
2016

learning-topics
Molecular and genetic factorsin disease
Almost all diseases have a genetic component. In children and young adults in particular, many of the disorders causing long-term morbidity and mortality are
genetically determined. The molecular basis of most
Mendelian (or ‘single-gene’) diseases has now been
determined, and our understanding of the abnormalities
in cell function responsible for the clinical presentation
is improving. It has also become clear that variants in
many genes contribute to the pathogenesis of several
common diseases such as asthma, rheumatoid arthritis
and osteoporosis. In this chapter, we review key principles
of cell biology, cellular signalling and molecular
genetics, with emphasis on the diagnosis and assessment
of patients with genetic diseases.
FUNCTIONAL ANATOMY AND PHYSIOLOGY
Cell and molecular biology
All human cell types are derived from a single totipotent
stem cell, the zygote (the fertilised ovum). During development, organs and tissues are formed by the integration of four closely regulated cellular processes: cell
division, migration, differentiation and programmed
cell death.In many adult tissues such as skin,liver and GIT ,
these processes continue throughout life, mediated by populations of stem cells that are responsible for tissue maintenance and repair. Cell biology is the study of these processes and of intracellular compartments, called organelles, which maintain cellular homeostasis. Dysfunction of any of these processes may lead to disease.
DNA, chromosomes and chromatin
The nucleus is a membrane-bound compartment foundin all cells except erythrocytes and platelets. The human
nucleus contains 46 chromosomes, each a single linear
molecule of deoxyribonucleic acid (DNA) complexed
with proteins to form chromatin. The basic protein unit
of chromatin is the nucleosome, comprising 147 base
pairs (bp) of DNA wound round a core of four different
histone proteins. The vast majority of chromosomal DNA is double-stranded, with the exception of the ends of chromosomes, where ‘knotted’ domains of single-stranded DNA, called telomeres, are found. Telomeres prevent degradation and accidental fusion of chromosomal DNA.
The genome comprises approximately 3.1 billion bp
of DNA. Humans are diploid organisms, meaning thateach nucleus contains two copies of the genome, visible
microscopically as 22 identical chromosomal pairs – the
autosomes – named 1 to 22 in descending size order, and two sex chromosomes (XX in females and XY in males). Each DNA strand consists of a linear sequence of four bases – guanine (G), cytosine (C), adenine (A) and thymine (T) – covalently linked by phosphate bonds. The sequence of one strand of double-stranded DNA determines the sequence of the opposite strand because the helix is held together by hydrogen bonds between adenine and thymine or guanine and cytosine nucleotides.
Genes and transcription
Genes are functional elements on the chromosome that
are capable of transmitting information from the DNA
template via the production of messenger ribonucleic acid (mRNA) to the production of proteins. The human genome contains an estimated 21 500 genes, although many of these are inactive or silenced in different cell types. For example, although the gene for parathyroid hormone (PTH) is present in every cell, activation of gene expression and production of PTH mRNA is virtually restricted to the parathyroid glands. Genes that are active in different cells undergo transcription, which requires binding of an enzyme called RNA polymerase II to a segment of DNA at the start of the gene termed the promoter.
Once bound, RNA polymerase II moves along one strand of DNA, producing an RNA molecule that is complementary to the DNA template. A DNA sequence close to the end of the gene, called the polyadenylation signal, acts as a signal for termination of the RNA transcript . The activity of RNA
polymerase II is regulated by transcription factors.
These proteins bind to specific DNA sequences at the
promoter, or to enhancer elements that may be many
thousands of base pairs away from the promoter. A loop
in the chromosomal DNA brings the enhancer close to
the promoter, enabling the bound proteins to interact.
The human genome encodes approximately 1200 different
transcription factors, and mutations in many of these can cause genetic diseases . Mutation of the transcription factor binding sites within promoters or enhancers also causes genetic disease. For example, the blood disorder alpha-thalassaemia can result from loss of an enhancer located more than 100 000 bp from the alpha-globin gene promoter, leading to greatly reduced transcription. Similarly, variation in the promoter of the gene encoding intestinal lactase determines whether or not this is ‘shut off’ in adulthood, producing lactose intolerance. The accessibility of promoters to RNA polymerase IIdepends on the structural configuration of chromatin.
Transcriptionally active regions have decondensed (or
‘open’) chromatin (euchromatin). Conversely, transcriptionally silent regions are associated with denselypacked chromatin called heterochromatin. Chemical
modification of both the DNA and core histone proteins
allows heterochromatic regions to be distinguished
from open chromatin. DNA can be modified by addition
of a methyl group to cytosine molecules (methylation).
In promoter regions, this silences transcription, since
methyl cytosines are usually not available for transcription
factor binding or RNA transcription.
The core histones can also be modified via methylation,
phosphorylation, acetylation or sumoylation at specific
amino acid residues in a pattern that reflects the functional
state of the chromatin; this is called the histone
code – reflecting an emerging understanding of the
‘rules’ by which specific modifications mark transcriptionally
activating (trimethylation of lysine 4 on histone
H3; acetylation of many histone residues) or silencing
(methylation of lysine 9 on histone H4; deacetylation of
many histone residues) effects. Such DNA and protein
modifications are termed epigenetic, as they do not
alter the primary sequence of the DNA code but have
biological significance in chromosomal function.
Abnormal epigenetic changes are increasingly recognised as important events in the progression of cancer, allowing
expression of genes which are normally silenced during
development to support cancer cell de-differentiation.
They also afford therapeutic targets.
For instance, the histone deacetylase inhibitor vorinostat
has been successfully used to treat cutaneous T-cell lymphoma, due to the re-expression of genes that had previously been silenced in the tumour. These genes encode
transcription factors which promote T-cell cell differentiation as opposed to proliferation, thereby causing
tumour regression.
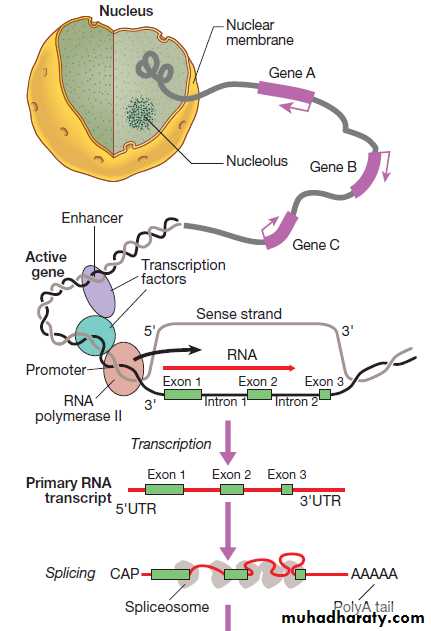
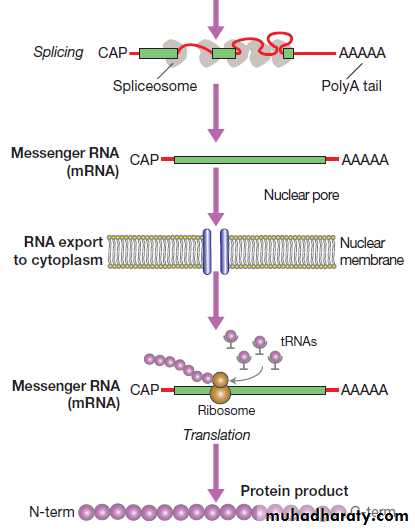
RNA synthesis and its translation into protein.
Fig. RNA synthesis and its translation into protein. Genetranscription involves binding of RNA polymerase II to the promoter of genes being transcribed with other proteins (transcription factors) that regulate the transcription rate. The primary RNA transcript is a copy of the whole gene and includes both introns and exons, but the introns are removed within the nucleus by splicing and the exons are joined to form the messenger RNA (mRNA). Prior to export from the nucleus, a methylated guanosine nucleotide is added to the 5′ end of the RNA (‘cap’) and a string of adenine nucleotides is added to the 3′ (‘poly A tail’). This protects the RNA from degradation and facilitates transport into the cytoplasm. In the cytoplasm, the mRNA binds to ribosomes and forms a template for protein production.
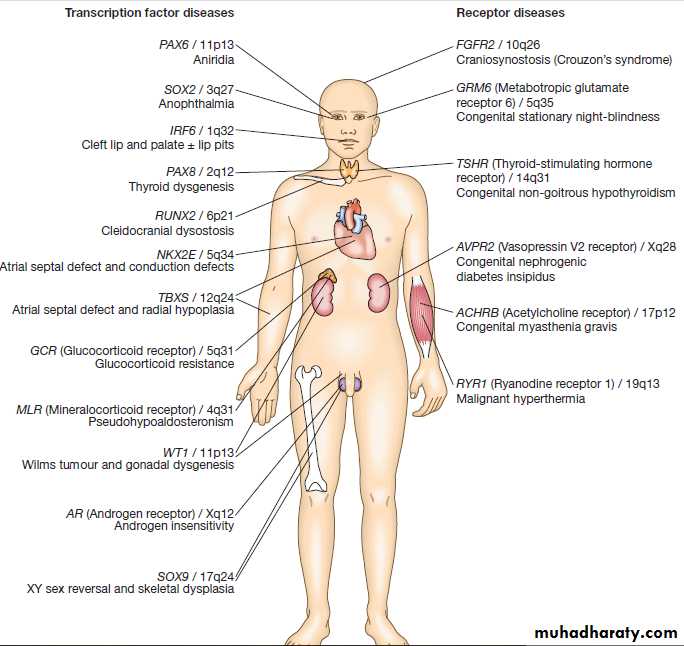
Examples of genetic diseases
caused by mutations in genes encoding either transcription factors or receptors.RNA splicing, editing and degradation
Transcription produces an RNA molecule that is a copyof the whole gene, termed the primary or nascent transcript.
RNA differs from DNA in three main ways:
• RNA is single-stranded.
• The sugar residue within the nucleotide is ribose,
rather than deoxyribose.
• Uracil (U) is used in place of thymine (T).
The nascent RNA molecule then undergoes splicing,
to generate the shorter, ‘mature’ mRNA molecule, which
provides the template for protein production.
Splicing removes the regions of the nascent RNA molecule that are not required to make protein (intronic regions), and retains and rejoins those segments that are necessary for protein production (exonic regions). Splicing is a highly
regulated process that is carried out by a multimeric
protein complex called the spliceosome. Following splicing,
the mRNA molecule is exported from the nucleus
and used as a template for protein synthesis. It should
be noted that many genes produce more than one form
of mRNA (and thus protein) by a process termed alternative splicing. Different proteins from the same gene
can have entirely distinct functions.
For example, in thyroid C cells the calcitonin gene produces mRNA encoding the osteoclast inhibitor calcitonin ,
but in neurons the same gene produces an mRNA
with a different complement of exons via alternative
splicing, which encodes the neurotransmitter calcitoningene-
related peptide. The portion of the mRNA molecule that directs synthesis of a protein product is called the open reading frame (ORF). This comprises a contiguous series of three sequential bases (codons), which specify that a particular amino acid should be incorporated into the protein. There are 64 different codons; 61 of these specify incorporation of one of the 20 amino acids, whereas the remaining three codons–UAA, UAG and UGA (stop codons) cause termination of the growing polypeptide chain.
In humans, most ORF start with the amino acid methionine,
which is specified by the codon AUG. All mRNA moleculeshave domains before and after the ORF called the
5′ untranslated region (5′UTR) and 3′UTR, respectively.
The start of the 5′UTR contains a cap structure that protects
mRNA from enzymatic degradation, and other
elements within the 5′UTR are required for efficient
translation. The 3′UTR also contains elements that regulate
efficiency of translation and mRNA stability, including
a stretch of adenine bases known as a polyA tail.
However, there are approximately 4500 genes in
humans in which the transcribed RNA molecules do
not code for proteins.
There are various categories of non-coding RNA (ncRNA), including transfer RNA (tRNA), ribosomal RNA (rRNA), ribozymes and micro- RNA (miRNA). There are more than 1000 miRNAs that bind to various target mRNAs, typically in the 3′UTR, to affect mRNA stability. This usually results in enhanced degradation of the target mRNA, leading to translational gene silencing. Together, miRNAs affect over half of all human genes and have important roles in normal
development, cancer and common degenerative disorders.
This is the subject of considerable research at present.
Translation and protein production
Following splicing and export from the nucleus, mRNAsassociate with ribosomes, which are the sites of protein
production (see Fig.). Each ribosome consists of two
subunits (40S and 60S), which comprise non-coding
rRNA molecules complexed with proteins. During
translation, tRNA binds to the ribosome.
The tRNAs deliver amino acids to the ribosome so that the newly synthesised protein can be assembled in a stepwise
fashion. Individual tRNA molecules bind a specific amino acid and ‘read’ the mRNA ORF via an ‘anticodon’ of three nucleotides that is complementary to the codon in mRNA.
A proportion of ribosomes are bound to the membrane of the endoplasmic reticulum (ER), a complex tubular structure that surrounds the nucleus.
Proteins synthesised on these ribosomes are translocated
into the lumen of the ER, where they undergo folding
and processing. From here the protein may be transferred
to the Golgi apparatus, where it undergoes
post-translational modifications, such as glycosylation
(covalent attachment of sugar moieties), to form the
mature protein that can be exported into the cytoplasm
or packaged into vesicles for secretion.
The clinical importance of post-translational modification of proteins is shown by the severe developmental, neurological, haemostatic and soft-tissue abnormalities that occur in patients with mutations of the enzymes that catalyse the addition of chains of sugar moieties to proteins. An example is phosphomannose isomerase deficiency, in which there is a defect in the conversion of fructose-6- phosphate to mannose-6-phosphate. This results in a defect in supply of D-mannose derivatives for glycosylation of a variety of proteins, resulting in a multi-system disorder characterised by protein-losing enteropathy, hepatic fibrosis, coagulopathy and hypoglycaemia.
Post-translational modifications can also be disrupted by
the synthesis of proteins with abnormal amino acidsequences. For example, the most common mutation in
cystic fibrosis (ΔF508) results in an abnormal protein that
cannot be exported from the ER and Golgi.
Mitochondria and energy production
The mitochondrion is the main site of energy productionwithin the cell. Mitochondria arose during evolution via the symbiotic association with an intracellular bacterium. They have a distinctive structure with functionally distinct inner and outer membranes. Mitochondria produce energy in the form of adenosine triphosphate (ATP). ATP is mostly derived from the metabolism of glucose and fat (Fig.). Glucose cannot enter mitochondria directly but is first metabolized to pyruvate via glycolysis. Pyruvate is then imported into the mitochondrion and metabolised to acetyl-coenzyme A (CoA). Fatty acids are transported into the mitochondria following conjugation with carnitine and are sequentially catabolised by a process called β-oxidation to produce acetyl-CoA.
The acetyl-CoA from both pyruvate and fatty acid oxidation is used in the citric acid (Krebs) cycle – a series of enzymatic reactions that produces CO2, NADH and FADH2. Both NADH and FADH2 then donate electrons to the respiratory chain. Here these electrons are transferred via a complex series of reactions resulting in the formation of a proton gradient across the inner mitochondrial membrane. The gradient is used by an inner mitochondrial membrane protein, ATP synthase, to produce ATP, which is then transported to other parts of the cell.
Dephosphorylation of ATP is used to produce the
energy required for many cellular processes.
Each mitochondrion contains 2–10 copies of a 16 kilobase
(kB) double-stranded circular DNA molecule(mtRNA). mtDNA contains 13 protein-coding genes, all
involved in the respiratory chain, and the ncRNA genes
required for protein synthesis within the mitochondria
(see Fig.). The mutational rate of mtDNA is relatively
high due to the lack of protection by chromatin. Several
mtDNA diseases characterised by defects in ATP production
have been described. mtDNA diseases are inherited exclusively via the maternal line .This unusual inheritance pattern exists because all mtDNA in an individual is derived from that person’s mother via the egg cell, as sperm contribute no mitochondria to the zygote.
Mitochondria are most numerous in cells with high metabolic demands, such as muscle, retina and the basal ganglia, and these tissues tend to be the ones most severely affected in mitochondrial diseases (Box). There are many other mitochondrial diseases that are caused by mutations in nuclear genes, which encode proteins that are then imported into the mitochondrion and are critical for energy production:
for example, Leigh’s syndrome and complex I deficiency.
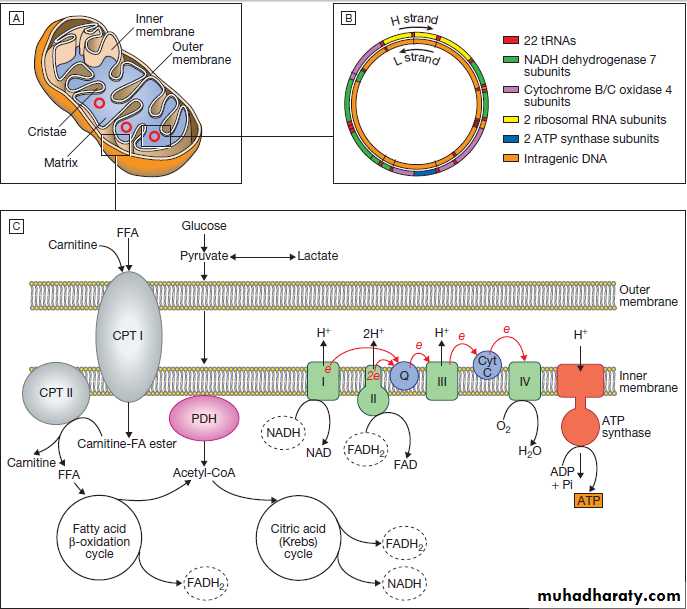
Fig. Mitochondria. A Mitochondrial structure. There is a smooth outer membrane surrounding a convoluted inner membrane, which has inward projections called cristae. The membranes create two compartments: the inter-membrane compartment, which plays a crucial role in the electron transport chain, and the inner compartment (or matrix), which contains mitochondrial DNA and the enzymes responsible for the citric acid (Krebs) cycle and the fatty acid β-oxidation cycle. B Mitochondrial DNA. The mitochondrion contains several copies of a circular double-stranded DNA molecule, which has a non-coding region, and a coding region which encodes the genes responsible for energy production, mitochondrial tRNA molecules and mitochondrial rRNA molecules. ATP = adenosine triphosphate; NADH = nicotinamide adenine dinucleotide.
C Mitochondrial energy production. Fatty acids enter the mitochondrion conjugated to carnitine by carnitine-palmityl transferase type 1 (CPT I) and, once inside the matrix, are unconjugated by CPT II to release free fatty acids (FFA). These are broken down by the β-oxidation cycle to produce acetyl-CoA.
Pyruvate can enter the mitochondrion directly and is metabolised by pyruvate dehydrogenase (PDH) to produce acetyl-CoA. The acetyl-CoA enters the Krebs cycle, leading to the production of NADH and
flavine adenine dinucleotide (reduced form) (FADH2), which are used by proteins in the electron transport chain to generate a hydrogen ion gradient across the inter-membrane compartment. Reduction of NADH and FADH2 by proteins I and II respectively releases electrons (e), and the energy released is used to pump protons into the inter-membrane compartment. As these electrons are exchanged between proteins in the chain, more protons are pumped across the membrane, until the electrons reach complex IV (cytochrome oxidase), which uses the energy to reduce oxygen to water. The hydrogen ion gradient is
used to produce ATP by the enzyme ATP synthase, which consists of a proton channel and catalytic sites for the synthesis of ATP from ADP. When the channel opens, hydrogen ions enter the matrix down the concentration gradient, energy is released that is used to make ATP.
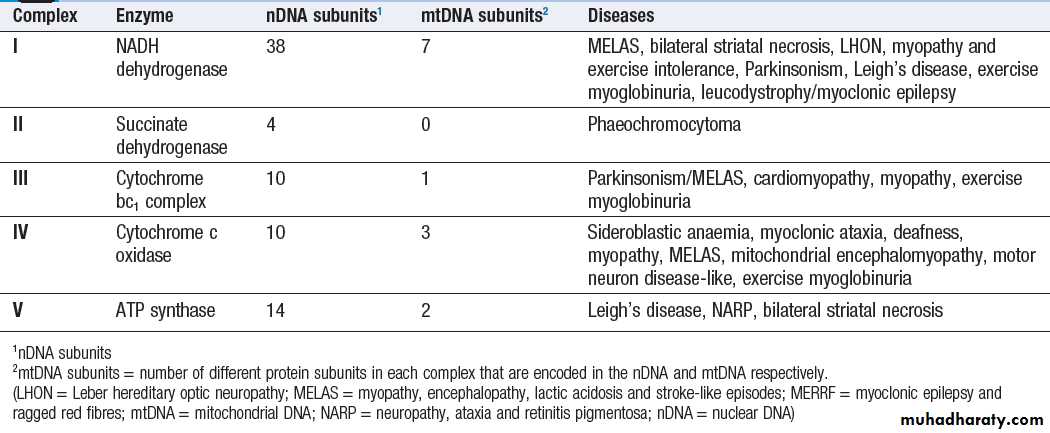
The structure of the respiratory chain complexes and the diseases associated with their dysfunction
Protein degradation
The cell uses several different systems to degrade proteinsand other molecules that are damaged, are potentially
toxic or have simply served their purpose. The
proteasome is the main site of protein degradation
within the cell. The first step in proteasomal degradation
is ubiquitination – the covalent attachment of a protein
called ubiquitin as a side chain to the target protein.
Ubiquitination is carried out by a large group of enzymes
called E3 ligases, whose function is to recognise specific
proteins that should be targeted for degradation by the
proteasome. The E3 ligases ubiquitinate their target
protein, which is then transported to a large multiprotein
complex called the 26S proteasome, where it is degraded.
There is mounting evidence that defects in the proteasome contribute to the pathogenesis of many diseases, particularly degenerative diseases of the nervous system like Parkinson’s disease and some typesof dementia that are characterised by formation of abnormal protein aggregates (inclusion bodies) within neurons. At least one inherited disease, termed Angelman’s syndrome, is due to a mutation affecting the UBE3 E3 ligase.
Proteins with complex post-translational modifications
are degraded in membrane-bound structures
called lysosomes, which have an acidic pH and contain
proteolytic enzymes that degrade proteins. There are
many inherited defects in lysosomal enzymes that result
in failure to degrade intracellular toxic substances.
For instance, in Gaucher’s disease, mutations of the gene
encoding lysosomal (acid) β-glucosidase lead to undigested lipid accumulating in macrophages, producinghepatosplenomegaly and, if severe, deposition in the
brain and mental retardation.
Lysosomes are also crucial for the process of autophagy,
a process of self-cannibalisation that allows the
cell to adapt to periods of starvation by recycling cellular
components. Autophagy is triggered by metabolic stress
and begins with the formation of a membrane-bound
vesicle called the autophagosome, which contains targeted
cellular components such as long-lived proteins and organelles. The autophagosome then fuses with the lysosome to start the degradation and recycling process.
Mutations in proteins that are crucial for formation of the autophagosome lead to neurodegenerative diseases in humans, such as juvenile neuronal ceroid lipofuscinosis (Batten’s disease), caused by autosomal recessive mutations in CLN3.
Peroxisomes are small, single membrane-bound
cytoplasmic organelles containing many different oxidative
enzymes such as catalase. Peroxisomes degrade
hydrogen peroxide, bile acids and amino acids.
However, the β-oxidation of very long-chain fatty acids
appears to be their most important function, since mutations in the peroxisomal β-oxidation enzymes (or the proteins that import these enzymes into the peroxisome) result in the same severe congenital disorder as mutations that cause complete failure of peroxisomal biogenesis.
This group of disorders is called Zellweger’s syndrome (cerebrohepatorenal syndrome) and is characterised by severe developmental delay, seizures, hepatomegaly and renal cysts; the biochemical diagnosis is made on the basis of elevated plasma levels of very long-chain fatty acids.
The cell membrane and cytoskeleton
The cell membrane is a phospholipid bilayer, withhydrophilic surfaces and a hydrophobic core (Fig.).
The cell membrane is, however, much more than a simple wall. Cholesterol-rich ‘rafts’ float within the membrane, and proteins are anchored to them via the post-translational addition of complex lipid moieties.
The membrane also hosts a series of transmembrane proteins that function as receptors, pores, ion channels, pumps and associated energy suppliers. These proteins allow the cell to monitor the extracellular milieu, import
crucial molecules for function, and exclude or exchange
unwanted substances.
Many protein–protein interactions within the cell membrane are highly dynamic, and individual peptides will associate and disassociate to effect specific roles. The cell membrane is permeable to hydrophobic substances, such as anaesthetic gases. Water is able to pass through the membrane via a pore formed by aquaporin proteins; mutations of an aquaporin gene cause congenital
nephrogenic diabetes insipidus . Most other molecules must be actively transported using either channels or pumps. Channels are responsible for the transport of ions and other small molecules across the cell membrane. They open and close in a highly regulated manner. The cystic fibrosis transmembrane conductance regulator (CFTR) is an example of an ion channel that is responsible for transport of chloride ions across epithelial cell membranes.
Mutation of the CFTR chloride channel, highly expressed in the lung and gut, leads to defective chloride transport, producing cystic fibrosis. Pumps are highly specific for their substrate and often use energy (ATP) to drive transport against a concentration gradient.
Endocytosis is a cellular process that allows internalisation
of larger complexes and molecules by invagination
of plasma membrane to create intracellular vesicles.
This process is typically mediated by specific binding
of the particle to surface receptors. An important
example is the binding of low-density lipoprotein (LDL)
cholesterol-rich particles to the LDL receptor (LDLR) in
a specialised region of the membrane called a clathrin pit.
In some cases of familial hypercholesterolaemia,
LDLR mutations cause failure of this binding
and thus reduce cellular uptake of LDL. Other LDLR
mutations change a specific tyrosine in the intracellular
tail of the receptor, preventing LDLR from concentrating
in clathrin-coated pits and hence impairing uptake of
LDL, even though LDLR bound to LDL is present elsewhere
in the cell membrane.
The shape and structure of the cell are maintained by
the cytoskeleton, which consists of a series of proteins
which form microfilaments (actin), microtubules (tubulins)
and intermediate filaments (keratins, desmin,
vimentin, laminins) that facilitate cellular movement
and provide pathways for intracellular transport.
Dysfunction of the cytoskeleton may result in a variety of
human disorders. For instance, some keratin genesencode intermediate filaments in epithelia.
In epidermolysis bullosa simplex , mutations in keratin genes (KRT5, KRT14) lead to cell fragility, producing the
characteristic blistering on mild trauma.
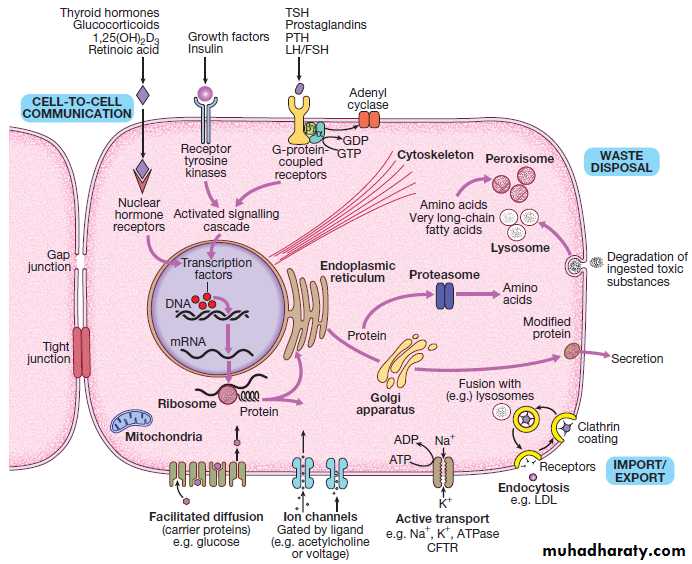
Fig. An archetypal human cell. The basic cell components required for function within a tissue: (1) cell-to-cell communication taking place via gap junctions and the various types of receptor that receive signals from the extracellular environment and transduce these into intracellular messengers; (2) the nucleus containing the chromosomal DNA; (3) intracellular organelles, including the mechanisms for proteins and lipid catabolism; (4) the cellular
mechanisms for import and export of molecules across the cell membrane. (ABC = ATP-binding cassette transporters; ATP = adenosine triphosphate:
cAMP = cyclic adenosine monophosphate; CFTR = cystic fibrosis transmembrane regulator; CREB = cAMP response element-binding protein; GDP/GTP = guanine diphosphate/triphosphate; LDL = low-density lipoproteins; LH/FSH = luteinising hormone/follicle-stimulating hormone; PTH = parathyroid hormone;
TSH = thyroid-stimulating hormone)
Receptors, cellular communication and intracellular signalling
Several mechanisms exist that allow cells to communicate with one another. Direct communication between adjacent cells occurs through gap junctions. These are pores formed by the interaction of ‘hemichannels’ in the membrane of adjacent cells. Many diseases are due to mutations in gap junction proteins, including the most common form of autosomal recessive hearing loss (GJB2) and the X-linked form of Charcot–Marie–Tooth disease (GJB1). Communication between cells that are not directly in contact with each other occurs through hormones, cytokines and growth factors, which bind to and activate receptors on the target cell.Receptors then bind to various other proteins within the cell termed signalling molecules, which directly or indirectly activate gene expression to produce a cellular response. There are many different signalling pathways; for
example, in nuclear steroid hormone signalling, the
ligands (steroid hormones or thyroid hormone) bind
to their cognate receptor in the cytoplasm of target
cells and the receptor/ligand complex then enters the
nucleus, where it acts as a transcription factor to regulate
the expression of target genes (Box). However, the
most diverse and abundant types of receptor are located
at the cell surface, and these activate gene expression
and cellular responses indirectly.
Activation of a cell surface receptor by its ligand results in a series of intracellular events, involving a cascade of phosphorylation of specific residues in target proteins by an important group of enzymes called kinases. This cascade typically culminates in phosphorylation and activation of transcription factors, which bind DNA and modulate gene expression.
Figure .depicts some of the signalling molecules
downstream of the tumour necrosis factor (TNF) receptor.
On activation of the receptor by the ligand (in this
case, TNF), other molecules, including TNF-receptorassociated proteins (TRAFs), are recruited to the intracellular domain of the receptor.
These regulate the activity of a kinase termed IKKγ, which in turn regulates activity of two further kinases termed IKKα and IKKβ. These regulate degradation of an inhibitory protein called IκB, which normally binds to the effector protein NFκB, holding it in the cytoplasm. On receptor activation, a signal is transmitted through TRAFs
and the IKK proteins to cause phosphorylation and degradation of IκB, allowing NFκB to translocate to the
nucleus and activate gene expression. The system also
has negative regulators, including the cylindromatosis
(CYLD) enzyme, which regulates the activity of TRAFs
by de-ubiquitination.
Other transmembrane receptors can be grouped into:
• ion channel-linked receptors (glutamate and thenicotinic acetylcholine receptor)
• G protein-coupled receptors (GnRH, rhodopsin,
olfactory receptors, parathyroid hormone receptor)
• receptors with kinase activity (insulin receptor,
erythropoietin receptor, growth factor receptors)
• receptors which have no kinase activity, but interact
with kinases via their intracellular domain when
activated by ligand (TNF receptor) .
Many receptors can signal only when they assemble
as a multimeric complex. Mutations which interfere
with assembly of the functional receptor multimer can
result in disease. For example, mutations of the insulin
receptor that inhibit dimerisation lead to childhood
insulin resistance and growth failure. Conversely, some
fibroblast growth factor receptor 2 (FGFR2) gene mutations
cause dimerisation in the absence of ligand binding,
leading to bone overgrowth and an autosomal dominant
form of craniosynostosis called Crouzon’s syndrome.
It is becoming clear that specialised projections on
the cell surface known as cilia are essential for normal
signalling in many tissues.
Cilia can be motile or nonmotile. Motile cilia are crucial for normal respiratory tract function, with primary ciliary dyskinesia (PCD) resulting in early-onset bronchiectasis due to failure to clear lung secretions. PCD is commonly associated with situs inversus (left–right laterality reversal) as a result of failure of a specific signalling process in very early embryogenesis. Mutations in proteins that are essential for non-motile cilia formation or function are responsible for a large number of autosomal recessive disorders known collectively as ciliopathies, which are commonly associated with intellectual disability, renal cystic dysplasia and retinal degeneration. For example, in the
Bardet–Biedl syndrome, mutations in a series of genes
encoding ciliary structure cause polydactyly, obesity,
hypogonadism, retinitis pigmentosa and renal failure.
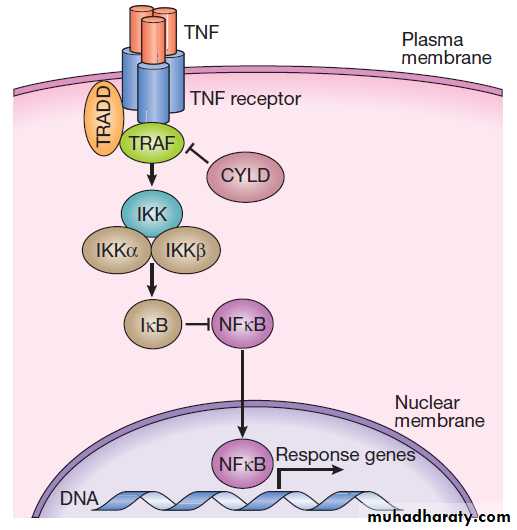
Fig. The tumour necrosis factor (TNF) signalling pathway.
TNF binds to its receptor, forming a trimeric complex in the cellmembrane. Various receptor-associated factors are attracted to the
intracellular domain of the receptor, including TNF-receptor-associated protein 6 (TRAF6) and tumour necrosis factor receptor type 1-associated death domain protein (TRADD). These proteins modulate activity of downstream signalling proteins, the most important of which are IKKγ (which in turn modulates activity of IKKα and IKKβ). These proteins cause phosphorylation of IκB, which is targeted for degradation by the proteasome, releasing NFκB, which translocates to the nucleus to activate gene expression. The signalling pathway is further regulated in a negative manner by cylindromatosis (CYLD), which de-ubiquitinates TRAF6, thereby
impairing its ability to activate downstream signalling.
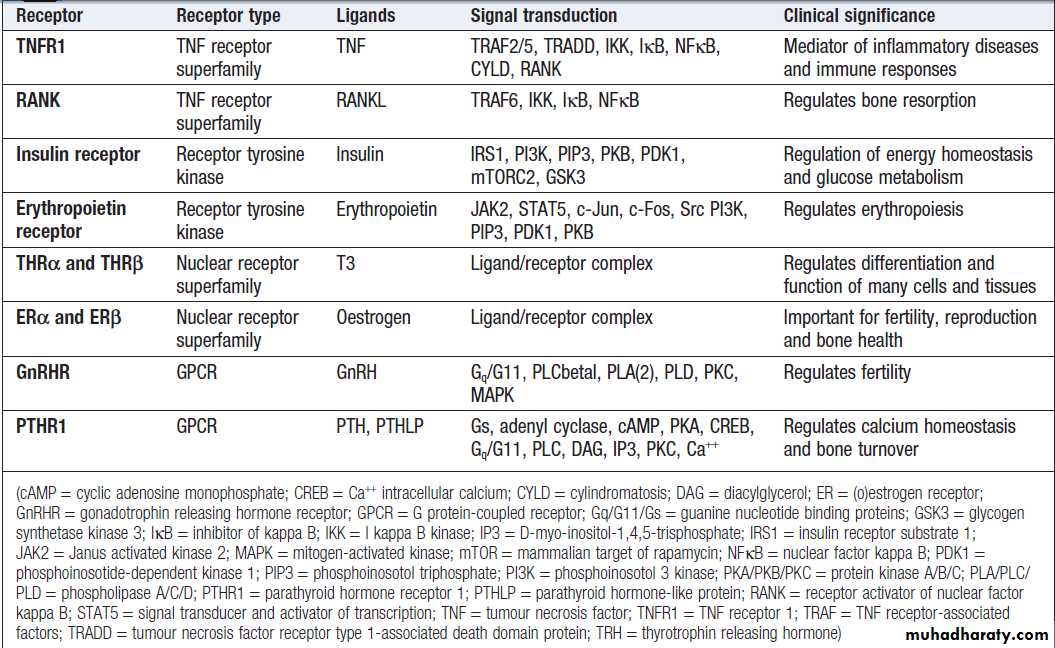
Examples of molecules involved in specific signalling cascades
Cell division, differentiation and migrationIn normal tissues, molecules such as hormones, growth
factors and cytokines provide the signal to activate the
cell cycle, a controlled programme of biochemical events
that culminates in cell division. During the first phase,
G1, synthesis of the cellular components necessary to
complete cell division occurs. In S phase, the cell produces
an identical copy of each chromosome – which carries the cell’s genetic information – via a process called DNA replication. The cell then enters G2, when any errors in the replicated DNA are repaired before proceeding to mitosis, in which identical copies of all chromosomes are segregated to the daughter cells.
The progression from one phase to the next is tightly controlled by cell cycle checkpoints. For example, the checkpoint between G2 and mitosis ensures that all damaged DNA is repaired prior to segregation of the chromosomes. Failure of these control processes is a crucial
driver in the pathogenesis of cancer.
During development, cells must become progressively
less like a stem cell and acquire the morphological
and biochemical configuration of the tissue to which
they will contribute. This process is called differentiation
and it is achieved by activation of tissue-specific genes
and inactivation or silencing of genes that maintain the
cell in a progenitor state.
This epigenetic process enables cells containing the same genetic material to have very different structures and functions. The programme of differentiation is often deranged or partially reversed in cancer cells. A similar mechanism allows adult stem cells to maintain and repair tissues. Cell migration is a process that is also necessary for development and wound healing. Migration also requires the activation of a specific set of genes, such as the transcription factor TWIST, that give the cell polarity and enable the leading edge of the cell to interact with the extracellular environment to control the speed and direction of travel. Again, this process can be reactivated in cancer cells and is thought to facilitate tumour metastasis.
Cell death, apoptosis and senescence
With the exception of stem cells, human cells haveonly a limited capacity for cell division. The Hayflick
limit is the number of divisions a cell population can go
through in culture before division stops and the cell
enters a state known as senescence. This ‘biological
clock’ is of great interest in the study of the normal
ageing process. Rare human diseases associated with
premature ageing, called progeric syndromes, have been
very helpful in identifying the importance of DNA repair mechanisms in senescence . For example, in Werner syndrome, a DNA helicase (an enzyme that separates the two DNA strands) is mutated, leading to failure of DNA repair and premature ageing.
A distinct mechanism of cell death is seen in apoptosis, or programmed cell death.
Apoptosis is an active process that occurs in normal
tissues and plays an important role in development,
tissue remodelling and the immune response. The signal
that triggers apoptosis is specific to each tissue or cell
type. This signal activates enzymes, called caspases,
which actively destroy cellular components, including
chromosomal DNA. This degradation results in cell
death, but the cellular corpse contains characteristic
vesicles called apoptotic bodies. The corpse is then recognised and removed by phagocytic cells of the immune
system, such as macrophages, in a manner that does not
provoke an inflammatory response.
A third mechanism of cell death is necrosis. This is a
pathological process in which the cellular environmentloses one or more of the components necessary for cell
viability.
Hypoxia is probably the most common cause
of necrosis.
GENETIC DISEASE AND INHERITANCE
MeiosisMeiosis is a special form of cell division that only occurs
in the post-pubertal testis and the fetal and adult ovary
(Fig.). Meiosis differs from mitosis in two main ways;
there are two separate cell divisions and before the first
of these there is extensive swapping of genetic material
between homologous chromosomes, a process known
as recombination. The result of recombination is that
each chromosome that a parent passes to his or her offspring is a mix of the chromosomes that the parent
inherited from his or her own mother and father.
The end products of meiosis are sperm and egg cells
(gametes), which contain only 23 chromosomes: one of
each homologous pair of autosomes and a sex chromosome. When a sperm cell fertilises the egg, the resulting zygote will thus return to a diploid chromosome complement of 46 chromosomes. The sperm determines the
sex of the offspring, since 50% of sperm will carry an X
chromosome and 50% a Y chromosome, while each egg
cell carries an X chromosome.
The individual steps in meiotic cell division are
similar in males and females. However, the timing of the
cell divisions is very different (see Fig.).
In females, meiosis begins in fetal life but does not complete until after ovulation. A single meiotic cell division can thus take more than 40 years to complete.
In males, meiotic division does not begin until puberty and continues throughout life. In the testes, both meiotic divisions are completed in a matter of days.
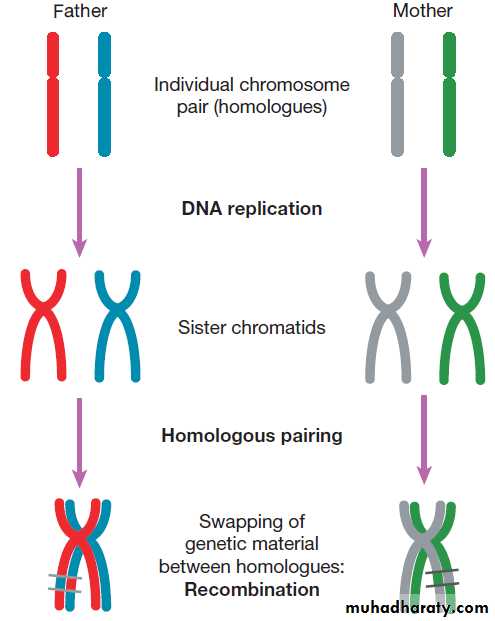
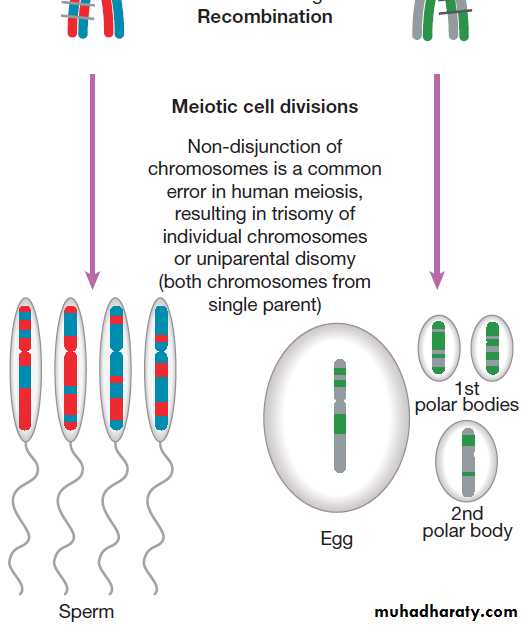
Fig. Meiosis and gametogenesis. The main chromosomal stages of meiosis in both males and females. A single homologous pair of chromosomes is represented in different colours. The final step is the production of haploid germ cells. Each round of meiosis in the male results in four sperm cells; in the female, however, only one egg cell is produced, as the other divisions are sequestered on the periphery of the mature egg
as peripheral polar bodies.
Patterns of disease inheritance
Five modes of genetic disease inheritance are discussed
below and illustrated in Figures.
Autosomal dominant inheritance
Autosomal dominant disorders result from a genetic
abnormality in one of the two copies (alleles) of a single
gene. The risk of an affected individual transmitting an
autosomal disease to his or her offspring is 50% for each
pregnancy, since half the affected individual gametes
(sperm or egg cells) will contain the affected chromosome
and half will contain the normal chromosome.
However, even within a family, individuals with the
same mutation rarely have identical patterns of disease
due to variable penetrance and/or expressivity.
Penetrance is defined as the proportion of individuals bearing a mutated allele who develop the disease phenotype. The mutation is said to be fully penetrant if all individuals who inherit a mutation develop the disease. Expressivity describes the level of severity of each aspect of the disease phenotype. Neurofibromatosis type 1 (NF1,
neurofibromin, 17q11.2) is an example of a disease that
is fully (100%) penetrant but which shows extremely
variable expressivity. The environmental factors and/or
variation in other genes that act as modifiers of the
mutated gene’s function are mostly unknown.
A good example of an environmental influence that can profoundly influence expression of autosomal dominant
disease is seen in the triggering of malignant hyperpyrexia
by anaesthetic agents in the presence of RYR1
mutations. Autosomal dominant disorders may be the
result of either loss or gain of function of the affected
gene. For example, adult polycystic kidney disease type
1 is caused by loss-of-function mutations in PKD1, which
encodes polycystin I on 16p13.1. Hereditary motor and sensory neuropathy type 1 is caused by increased number of copies (resulting in increased gene dosage) of PMP22, encoding peripheral myelin protein 22 on 17p11.2.
Autosomal recessive inheritance
In autosomal recessive disorders, both alleles of a genemust be mutated before the disease is manifest in an
individual, and an affected individual must inherit one
mutant allele from each parent. What distinguishes
autosomal dominant and recessive diseases is that
carrying one mutant allele does not produce a disease
phenotype. Autosomal recessive disorders are rare in
most populations. For example, the most common
serious autosomal recessive disorder in the UK is cystic
fibrosis, which has a birth incidence of 1 : 2000.
The frequency of autosomal recessive disorders increases with the degree of inbreeding of a population because the risk of inheriting the same mutant allele from both parents
(homozygosity) is increased.
Genetic risk calculation for a fully penetrant autosomal recessive disorder is straightforward. Each subsequent pregnancy of a couple who have had a previous child affected by an autosomal recessive disorder will have a 25% (1 : 4) risk of being affected; a healthy individual who has a sibling with an autosomal recessive disorder will have 2/3 chance of being a carrier. The risk of an affected individual having children with the same condition is usually low but is dependent on the carrier rate of the mutant allele in the population.
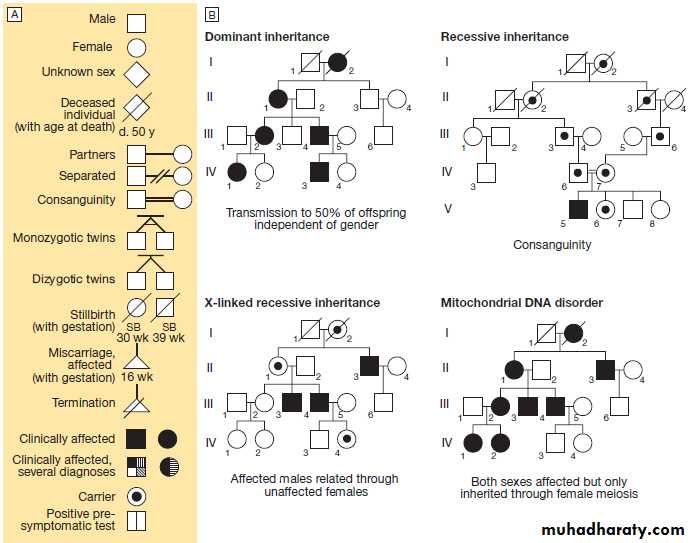
Fig. Drawing a pedigree and patterns of inheritance.
A The main symbols used to represent pedigrees in diagrammatic form.B The main modes of disease inheritance
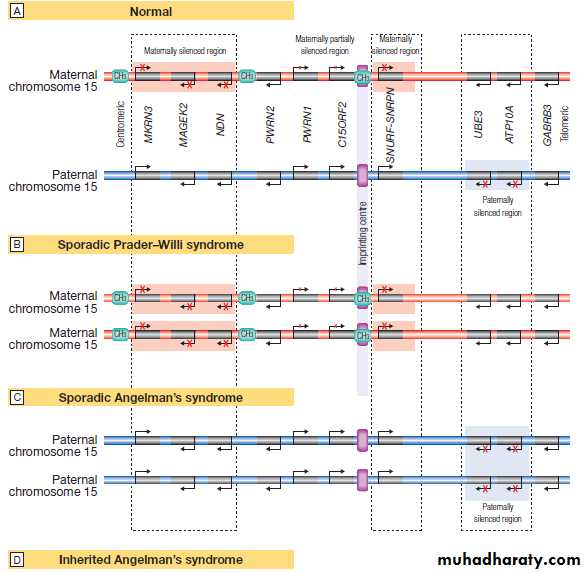
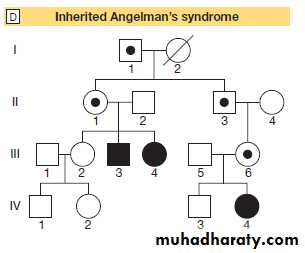
Fig. Genomic imprinting and associated diseases. Several regions of the genome exhibit the phenomenon of imprinting, whereby expression of one or a group of genes is influenced by whether the chromosome is derived from the mother or the father; one such region lies on chromosome 15. A Normal imprinting. Under normal circumstances, expression of several genes is suppressed (silenced) on the maternal chromosome (red), whereas these genes are expressed normally by the paternal chromosome (blue). However, two genes in the paternal chromosome (UBE3 and ATP10A) are silenced. B In sporadic Prader–Willi syndrome, there is a non-disjunction defect on chromosome 15, and both copies of the chromosomal region are derived from the mother (maternal uniparental disomy).
In this case, Prader–Willi syndrome occurs because there is loss of function of several paternally expressed genes, including MKRN3, MAGEK2, NDN, PWRN2, C15ORF2 and SNURF-SNRNP.
C In sporadic Angelman’s syndrome, both chromosomal regions are derived from the father (paternal uniparental disomy) due to non-disjunction during paternal meiosis. As a result, both copies of the UBE3 gene are silenced and this causes Angelman’s syndrome. Note that the syndrome can also be caused by deletion of this region on the maternal chromosome or a loss-of-function mutation on the maternal copy of UBE3, causing an inherited form of Angelman’s, as illustrated in panel D. D Pedigree of a family with inherited Angelman’s syndrome due to a loss-of-function mutation in UBE3. Inheriting this mutation from a father causes no disease (because the gene is normally silenced in the paternal chromosome) (see individuals I-1, II-1, II-3, III-6), but the same mutation inherited from the mother causes the syndrome (individuals III-3, III-4, IV-4), as this is the only copy expressed and the UBE3 gene is mutated.
X-linked inheritance
Genetic diseases caused by mutations on the X chromosomehave specific characteristics. X-linked diseases are mostly recessive and restricted to males who carry the mutant allele. This is because males have only one X chromosome, whereas females have two.
Thus females who carry a single mutant allele are generally unaffected. Occasionally, female carriers may exhibit signs of an X-linked disease due to a phenomenon called skewed X-inactivation.
All female embryos, at about 100 cells in size, stably inactivate one of their two X chromosomes in each cell.
This process is random in each cell but if, by chance, there is a disproportionate inactivation of normal X chromosomes carrying the normal allele, then an affected female carrier will be more likely, an extreme example being the rare cases of carrier females affected with Duchenne muscular dystrophy. These disorders have a recognisable pattern of inheritance, with transmission of the disease from carrier females to affected males and absence of father-to-son transmission. The risk of a female carrier having an affected child is 25% (1 : 4; half of her male offspring). If the carrier status of a woman is unclear, then the risk may be altered by conditional information, as in the autosomal dominant disease section above. Bayes’ theorem is commonly used to calculate such modified risks.
Mitochondrial inheritance
The inheritance of mtDNA disorders is characterised bytransmission from females, but males and females are
generally affected equally. Unlike the other inheritance
patterns mentioned above, mitochondrial inheritance
has nothing to do with meiosis but reflects the fact that
mitochondrial DNA is transmitted by oِcytes. Mitochondrial
disorders tend to be very variable in penetrance
and expressivity within families, and this is mostly accounted for by the fact that only a proportion
of multiple mtDNA molecules within mitochondria contain the causal mutation (the degree of mtDNA heteroplasmy).
Epigenetic inheritance and imprinting
Several chromosomal regions (loci) have been identified
where gene repression is inherited in a parent-of-originspecific manner; these are called imprinted loci. Within these loci the paternal alleles of a gene may be active while the maternal one may be silenced, or vice versa . Mutations within imprinted loci lead to a very unusual pattern of inheritance in which the phenotype is only manifest if inherited from the parent
who contributes the transcriptionally active allele. Examples of these disorders are given in Box.


Epigenetic disease

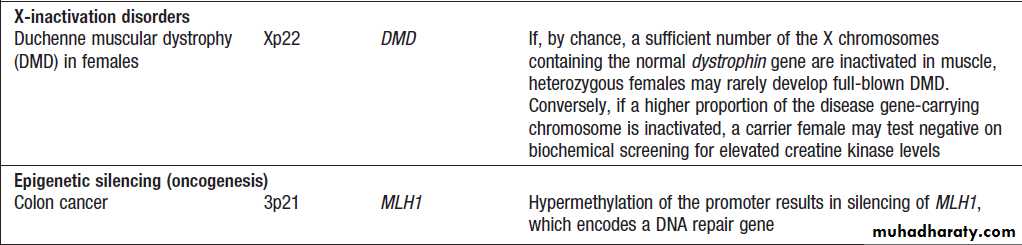
Epigenetic disease – cont’d
Classes of genetic variantThere are many different classes of variation in the
human genome . Rare genetic variations that result in a disease are generally referred to as mutations, whereas common variations and those that do not cause disease are referred to as polymorphisms.
These different types of variation are further categorised
by the size of the DNA segment involved and/or by the
mechanism giving rise to the variation.
Nucleotide substitutions
The substitution of one nucleotide for another is the
most common type of variation in the human genome.
Depending on their frequency and functional consequences,
these changes are known as a point mutation
or a single nucleotide polymorphism (SNP). They occur
by misincorporation of a nucleotide during DNA synthesis
or by the action of a chemical mutagen.
When these substitutions occur within ORFs of a proteincoding gene, they are further classified into:
• synonymous – resulting in a change in the codon
but no change in the amino acid and thus no
phenotype
• missense – altering a codon, resulting in an amino
acid change in the protein
• nonsense – introducing a premature stop codon,
resulting in truncation of the protein
• splicing – occurring at the junction of an intron and
an exon, thereby adversely affecting splicing.
Insertions and deletions
One or more nucleotides may be inserted or lost in aDNA sequence, resulting in an insertion/deletion (indel)
polymorphism or mutation . If an indel change affects one or two nucleotides within the ORF of a protein-coding gene, this can have serious consequences because the triple nucleotide sequence of the codons is disrupted, resulting in a frameshift mutation.
The effect upon the gene is typically severe because the
amino acid sequence is totally disrupted.
Simple tandem repeat mutation
Variations in the length of simple tandem repeats of
DNA are thought to arise as the result of slippage of
DNA during meiosis and are termed microsatellite
(small) or minisatellite (larger) repeats. These repeats
are unstable and can expand or contract in different
generations. This instability is proportional to the size
of the original repeat, in that longer repeats tend to be
more unstable. Many microsatellites and minisatellites
occur in introns or in chromosomal regions between
genes and have no obvious adverse effects. However,
some genetic diseases, including Huntington’s disease
and myotonic dystrophy, are caused by microsatellite
repeats, which result in duplication of amino acids
within the affected gene product or affect gene expression.
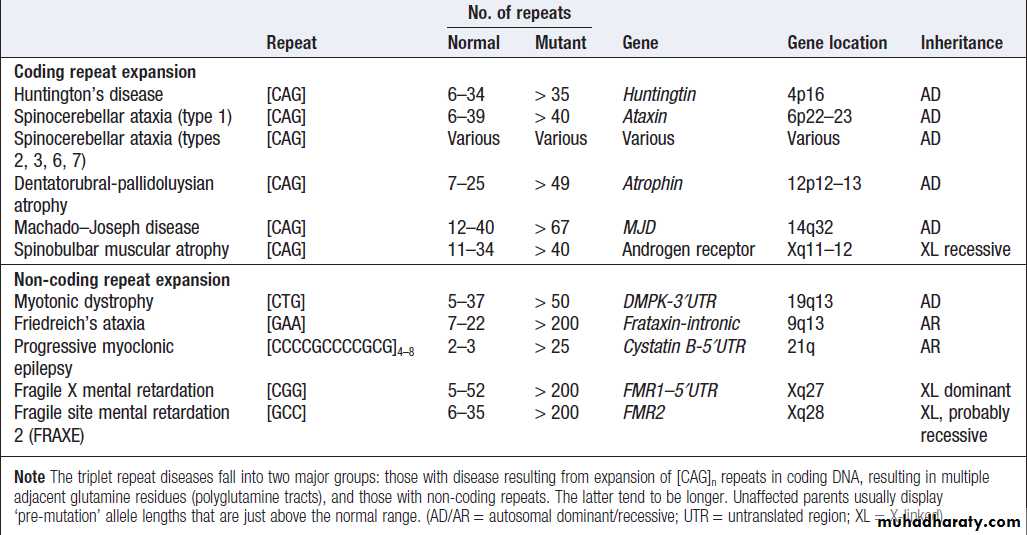
Diseases associated with triplet and other repeat sequences
Copy number variations
Variation in the number of copies of an individual
segment of the genome from the usual diploid (two
copies) content can be categorised by the size of the segment involved. Rarely, individuals may gain or lose
a whole chromosome. Such numerical chromosome
anomalies most commonly occur by a process known as
meiotic non-dysjunction (Box). This is the most
common cause of Down’s syndrome, which results from
trisomy (three copies) of chromosome 21.
Large insertions or deletions of chromosomal DNA
also occur and are usually associated with learning
disability and/or malformations.
Such structural chromosomal anomalies arise as the result of two different processes:
• non-homologous end-joining• non-allelic homologous recombination.
Random double-stranded breaks in DNA are a necessary
process in meiotic recombination and also occur
during mitosis at a predictable rate. The rate of these
breaks is dramatically increased by exposure to ionising
radiation. When such breaks occur, they are usually
repaired accurately by DNA repair mechanisms within
the cell. However, a proportion of breaks undergoes
non-homologous end-joining, which results in the joining of two segments of DNA that are not normally contiguous.
If the joined fragments are from different chromosomes, this results in a translocation. If they are from the same chromosome, this will result in inversion, duplication or deletion of a chromosomal fragment . Large insertions and deletions may be cytogenetically visible as chromosomal deletions or duplications.
If the anomalies are too small to be detected by
microscopy, they are termed microdeletions and microduplications.
Many microdeletion syndromes have been described and most stem from non-allelic homologous recombination between repeats of highly similar DNA sequences, which results in identical chromosome anomalies – and clinical syndromes – occurring in unrelated individuals.

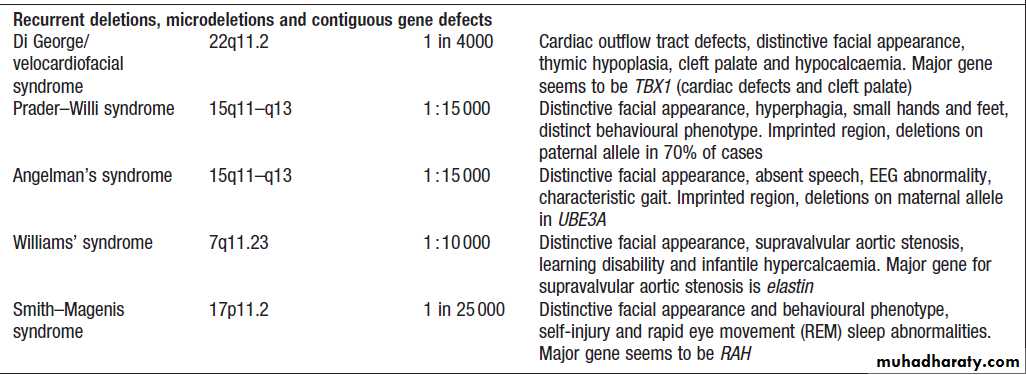
Polymorphic copy number variants
In addition to the disease-causing structural chromosomalanomalies mentioned above, there are also a considerable number of polymorphic CNVs that exist as common genetic polymorphisms in humans. These involve duplication of large segments of the genome, often containing multiple genes and regulatory elements.
These duplications usually result from non-allelic
homologous recombination via misalignment of tandem repeated DNA elements in the chromosome during
recombination . The consequences of CNV for genetic disease have not been fully explored, although
recent studies have shown a strong association between
an increased copy number of the gene FCGR3B and the
risk of systemic lupus erythematosus.
Consequences of genetic variation
Can generally be classed into three groups:
• those associated with no detectable change in gene
function (neutral variants)
• those which cause a loss of function of the gene product
• those which cause a gain of function of the gene product.
The consequence of an individual mutation depends
on many factors, including the mutation type, the nature
of the gene product and the position of the variant in the
protein. Mutations can have profound effects or subtle
effects on gene and cell function (Box). Variations
that have profound effects are responsible for ‘classical’
genetic diseases, whereas those with subtle effects may
contribute to the pathogenesis of complex diseases with
a genetic component.
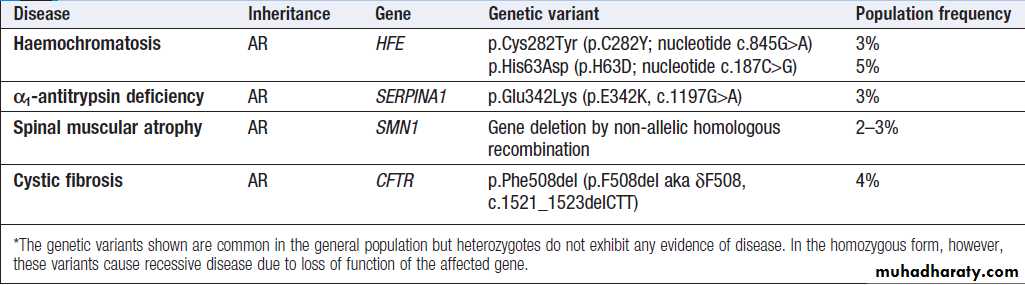
Examples of recessive diseases caused by common genetic variants*
Loss-of-function mutations
These mutations cause the normal function of a protein
to be reduced or lost. Deletion of the whole gene is the
most extreme example but the same phenotype can be
seen with a nonsense or frameshift mutation early in the
ORF. Missense mutations that alter a critical domain
within the protein can also result in loss of function.
In autosomal recessive diseases, mutations that result
in no protein function whatsoever are known as null
mutations. If loss-of-function mutations result in an
autosomal dominant disease, the genetic mechanism is
known as haploinsufficiency and indicates that both
functional copies of the gene are required for normal
cellular function. Mutations in PKD1 or 2 that cause
AD adult polycystic kidney are mostly loss of function.
Gain-of-function and dominant negative mutations
Gain-of-function and dominant-negative effect mutationsare most commonly the result of missense mutation
or in-frame deletions but may also be caused by
triplet repeat expansion mutations. Gain of function
results where a mutation alters the protein structure,
causing activation of its normal function, causing it to
interact with a novel substrate or causing it to change its
normal function. Constitutive activation of fibroblast
growth factor receptors by missense mutation, which
leads to many disorders such as achondroplasia, is an
example of a gain-of-function mutation.
Dominant-negative mutations are heterozygous changes that have a more deleterious effect on the protein function than a heterozygous ‘null’ mutation. For example, heterozygous mutations in FBN1 cause Marfan’s syndrome by the production of a protein with an abnormal amino acid sequence that disrupts the normal assembly of microfibrils.
In comparison, complete loss of function of one
allele of FBN1 is usually completely benign.
Polymorphisms
A polymorphism is defined as a change in the nucleotidesequence that exists with a population frequency of
more than 1%. Most common polymorphisms are
neutral (see below), but some cause subtle changes in gene expression or in protein structure and function. It is thought that these polymorphisms lead to variations in phenotype within the general population, including variations in susceptibility to common diseases. An example is polymorphism in the gene SLC2A9 that not only explains a significant proportion of the normal population variation in serum urate concentration but also predisposes ‘high-risk’ allele carriers to the development of gout.
Neutral variants
The vast majority of variations within the humangenome have no discernible effect on the cell or organism.
This may be because the variation is non-coding,
occurring outside the gene but within an intron, or is
within the coding regions of a gene but does not change
the amino acid because of a synonymous substitution at
the third base of a codon . Some variations
that do change the amino acid may be completely tolerated with regard to protein function.
Evolutionary selection
Genetic variants play an important role in evolutionaryselection; some are advantageous to an organism, resulting
in positive selection through evolution via improved
reproductive fitness. However, variations that decrease
reproductive fitness become less common and are
excluded through evolution. Given this simple paradigm,
it would be tempting to assume that common
mutations are all advantageous and all rare mutations
are pathogenic. Unfortunately, it is often difficult to classify
any common mutation as either advantageous or
deleterious – or, indeed, neutral.
Mutations that are advantageous in early life and thus enhance reproductive fitness may be deleterious in later life. There may be mutations that are advantageous for survival in particular conditions (for example, famine or pandemic), which may be disadvantageous in more benign circumstances by resulting in a predisposition to obesity or
autoimmune disorders. This complexity of balancing
selection through evolution is likely to be an important
feature of the genetics of common disease.
Constitutional genetic disease
All familial genetic disease is caused by constitutional mutations, which are inherited through the germ line. However, different mutations in the same gene can have different consequences, depending on the genetic mechanism underlying that disease.About 1% of the population carries constitutional mutations that cause disease.
Allelic heterogeneity
Allelic heterogeneity is where several different mutationscause the same phenotype. This is seen in almost
all genetic disease. In familial adenomatous polyposis
coli, whole-gene deletions, nonsense mutations,
frameshift mutations and some missense mutations
result in exactly the same phenotype because they all
cause loss of function in the FAP gene on chromosome
5q. Many other Mendelian disorders show this phenomenon
with loss-of-function mutations, including adult
polycystic kidney disease (PKD1, 16p13; PKD2, 4q21).
Allelic heterogeneity can also be seen in gain-of-function
and dominant-negative mutations.
In connective tissue disorders, dominant-negative mutations are almost always missense mutations or in-frame deletions or insertions, since the aberrant protein has to be made for
the disease to manifest. In most diseases caused by gainof-
function mutations, allelic heterogeneity is severely
restricted. A good example of this is achondroplasia, in
which the mutations in FGFR3 are restricted to a few
specific codons that cause constitutive activation of the
receptor that is required to cause the disease.
Locus heterogeneity
Locus heterogeneity is where a similar phenotype resultsfrom mutations in several different genes. One of the
best examples is retinitis pigmentosa, which can occur
as the result of mutations in more than 75 genes, each of
which has a different chromosomal location.
De novo mutations
Although the vast majority of constitutional mutations
are inherited, each gamete will contain mutations that
have occurred as a result of meiosis; these are called de
novo mutations. Each individual has approximately 70
de novo mutations scattered throughout their genome.
This occurs in each generation and is presumably
required for evolution to occur. Most are neutral but
such mutations may also cause human disease. De novo
mutations cause severe congenital disorders such as
thanatophoric dysplasia (FGFR3 gain-of-function mutation),
bilateral anophthalmia (SOX2 haploinsufficiency),
campomelic dysplasia (SOX9 loss of function) and the severe form of osteogenesis imperfecta
(dominant-negative mutations in COL1A1 or COL1A2).
Somatic genetic disease
Somatic mutations are not inherited but instead occurduring post-zygotic mitotic cell divisions at any point
from embryonic development to late adult life. An
example of this phenomenon is polyostotic fibrous dysplasia (McCune–Albright syndrome), in which a somatic
mutation in the GS alpha gene causes constitutive activation
of receptor signalling downstream of many G
protein-coupled receptors, resulting in focal lesions in
the skeleton and endocrine dysfunction . The most important example of human disease caused by somatic mutations is cancer. Here, ‘driver’ mutations occur within genes that are involved in regulating cell division or apoptosis, resulting in abnormal cell growth and tumour formation.
The two general categories of cancer-causing mutation are gain-of-function mutations in growth-promoting genes (oncogenes) and loss-of-function mutations in growth-suppressing genes (tumour suppressor genes). Whichever mechanism is acting, most tumours require an initiating mutation in a single cell that can then escape from normal growth controls. This cell replicates more frequently or fails to undergo programmed death, resulting in clonal expansion.
As the size of the clone increases, one or more cells
may acquire additional mutations that confer further
growth advantage, leading to proliferation of these
subclones, which may ultimately lead to aggressive
metastatic cancer.
The cell’s complex self-regulating machinery means that more than one mutation is usually required to produce a malignant tumour . For example, if a mutation results in activation of a growth factor gene or receptor, then that cell will replicate more frequently as a result of autocrine stimulation.
However, this mutant cell will still be subject to normal cell cycle checkpoints to promote DNA integrity in its progeny. But if additional mutations in the same cell result in defective cell cycle checkpoints, it will rapidly accumulate further mutations, which may allow completely unregulated growth and/or separation from its matrix and cellular attachments and/or resistance to apoptosis.
As cell growth becomes increasingly dysregulated,
cells de-differentiate, lose their response to normal tissue environment and cease to ensure appropriatemitotic chromosomal segregation. These processes
combine to generate the classical malignant
characteristics of disorganised growth, variable levels of
differentiation, and numerical and structural chromosome
abnormalities. An increase in somatic mutation rate can occur on exposure to external mutagens, such as ultraviolet light or cigarette smoke, or if the cell has defects in DNA repair systems. Cancer therefore affects the fundamental processes of molecular and cell biology.
In many familial cancer syndromes, somatic mutations
act together with an inherited mutation to causecancer. Familial cancer syndromes may be due to lossof-
function mutations in tumour suppressor genes or
genes encoding DNA repair enzymes. In DNA repair
diseases, the inherited mutations increase the somatic
mutation rate. Autosomal dominant mutations in genes
encoding components of specific DNA repair systems
are relatively common causes of familial colon cancer
and breast cancer (e.g. BRCA1). Autosomal recessive
DNA repair disorders are rare and are associated with
almost complete loss of DNA repair enzymes.
This is usually associated with a severe multifaceted degenerative disorder with cancer susceptibility as a significant component (e.g. xeroderma pigmentosum).
Cancer syndromes are also caused by loss-of-function
mutations in tumour suppressor genes. At the cellular
level, loss of one functional copy of a tumour suppressor
gene does not have any functional consequences, as the
cell is protected by the remaining normal copy. However,
a somatic mutation affecting the normal allele is likely
to occur in one cell at some point during life, resulting
in complete loss of tumour suppressor activity and a
tumour developing by clonal expansion of that cell.
This two-hit mechanism (one inherited, one somatic) for
cancer development is known as the Knudsen hypothesis.It explains why tumours may not develop for many
years (or ever) in some members of these cancer-prone
families. Yet another group of cancer syndromes are the
result of gain-of-function mutations in tumour promoter
genes (proto-oncogenes).
INVESTIGATION OF GENETIC DISEASE
General principles of diagnosisMany genetic diseases can be diagnosed by a careful
clinical history and examination together with an
awareness and knowledge of rare diseases. Although
DNA-based diagnostic tools are now widely used, not
all diagnostic genetic tests involve analysis of DNA. For
example, an electrocardiogram (ECG) can establish the
diagnosis in long QT syndrome or a renal ultrasound
can detect adult polycystic kidney disease.
By definition, all genetic testing (whether DNA-based or not) has implications for both the patient and other members of the family.
These issues should be considered before genetic testing is undertaken and a plan should be in place to deliver medical information and support to family members and to organise any relevant down-stream investigations.
Constructing a family tree
The family tree – or pedigree – is fundamental to the
diagnosis of genetic diseases. The basic symbols and
nomenclature used in drawing a pedigree are shown in
Figure above . A three-generation family history
taken in a routine medical clerking may reveal important
genetic information of relevance to the presenting
complaint, particularly relating to cancer.
A pedigree should include details from both sides
of the family, any history of pregnancy loss or infantdeath, consanguinity, and details of all medical conditions
in family members, including dates of birth and
age at death. It is important to be aware that a diagnosis given by a family member, or even obtained from a death certificate, may be wrong. This is often true in cases of cancer, where ‘stomach’ may mean any part of the bowel, and ‘brain’ may refer to secondary deposits or be used where the primary site has not been identified.
Polymerase chain reaction and DNA sequencing
The polymerase chain reaction (PCR) is a fundamentallaboratory technique that amplifies targeted sections
of the human genome for DNA diagnostic analysis.
Almost any tissue can be used to extract DNA for
PCR analysis, but most commonly, a sample of peripheral blood is used. PCR is very often used in association with DNA sequencing to determine the exact
nucleotide sequence of a specific region of a gene
or chromosome. The principles of PCR are shown in
Figure. The technique of DNA sequencing is used
for DNA diagnostic analysis in clinical practice.
Until recently, most diagnostic DNA laboratories used
Sanger sequencing for diagnosis , but increasingly this is being replaced by next-generation sequencing, which has higher throughput
Assessing DNA copy number
For decades, metaphase chromosome analysis by lightmicroscopy has been the mainstay of clinical cytogenetic
analysis to detect gain or loss of whole chromosomes or
large chromosomal segments (> 4 million bp); such
anomalies are collectively known as aneuploidy. More
recently, whole-genome microarrays have replaced
chromosome analysis, allowing rapid and precise detection
of segmental gain or loss of DNA throughout the
genome .Microarrays consist of dense grids of short sequences of DNA (probes) that are complementary to known sequences in the genome . Each probe is fixed at a known position on the array (often printed on to a specially coated glass slide).
The patient’s fluorescently labelled DNA sample
is hybridised to the array, and results for each probe areread by a laser scanner. This allows a copy number map
of the patient’s DNA to be constructed and abnormalities
to be identified. Many clinically recognisable syndromes
are the result of aneuploidy. The specific
phenotype associated with individual deletion syndromes
is the result of loss of one copy of several adjacent
genes – a contiguous gene syndrome .
Fluorescent in situ hybridisation (FISH) can be used to confirm specific deletions or duplications on metaphase chromosomes as a follow-up to microarray analysis.
Non-DNA-based methods of assessment
Although DNA-based diagnostic tools are used in the
majority of patients with suspected genetic disease, direct analysis of protein function, such as measurement of specific enzyme activity, can also be used to diagnose
single-gene disorders. An example of this is the investigation of myopathy thought to be due to defects in mitochondrial complex 1 proteins (Box). Complex 1 is
made up of at least 36 nuclear-encoded and 7 mitochondrial DNA-encoded subunits, and mutations in any of these subunits can cause the disorder, which makes
sequence analysis impractical as a first-line clinical test.
Conversely, the biochemical measurement of respiratory
chain complex I proteins can easily be analysed in muscle biopsies, and this can be diagnostic of a specific mitochondrial cytopathy.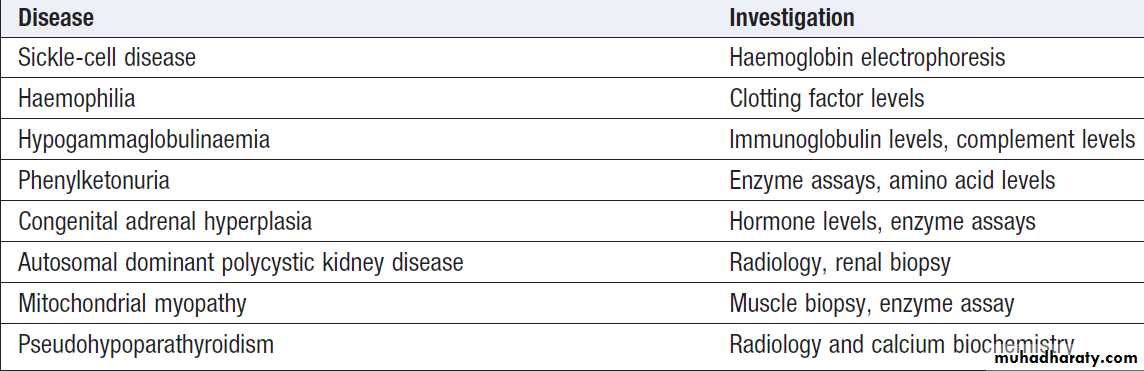
Examples of non-DNA-based investigations for common genetic diseases
Genetic testing in pregnancy and pre-implantation genetic testingGenetic testing may be performed during pregnancy.
Invasive tests, such as amniocentesis and chorionic villus sampling, are most often carried out to diagnose
conditions that result in early infant death or severe disability.
Such tests are only offered after careful explanation
of the risks involved. Many couples will use the
result of such tests to decide about termination of pregnancy.
Some indications for testing are listed in Box; the methods used are summarised in Boxes.
Non-invasive ultrasound scanning is offered to all pregnant
couples and is particularly important if there is a
previous history of serious developmental
abnormalities.
It is now possible to test single cells from a developing
human embryo for the presence of deleterious
mutations to select unaffected embryos as part of in vitro
fertilisation procedures. As the range of tests for genetic
diseases increases, demand for prenatal testing and preimplantation genetic diagnosis is likely to rise. There is
considerable ethical debate about the types of disease for
which such procedures are appropriate.

Some indications for prenatal testing
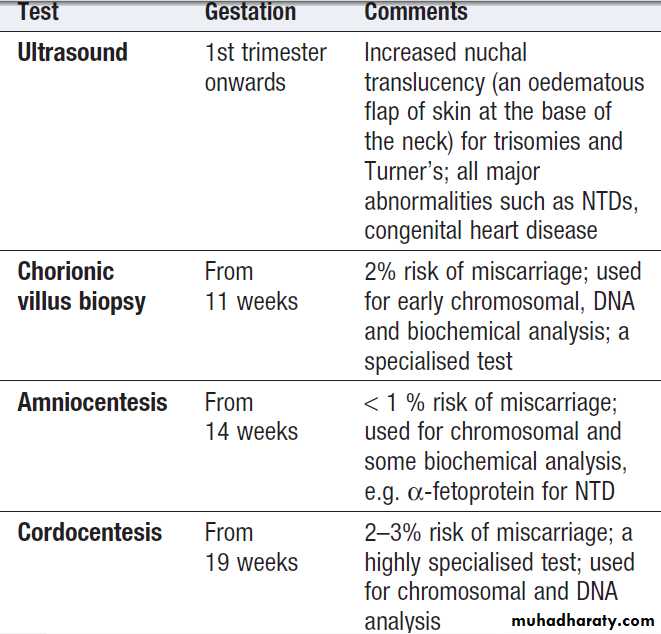
Methods used in prenatal testing


Screening for Down’s syndrome
Genetic testing in childrenEthical issues often arise with regard to genetic testing
of children. For conditions with onset during childhood and for which useful medical interventions are available,
it is clearly important to test a child. An example
of this is neonatal testing for cystic fibrosis, when early
therapy reduces disease progression or in multiple endocrine neoplasia type 2B (MEN 2B), when early thyroidectomy prevents medullary thyroid carcinoma.
However, testing a healthy child for an adultonset
disorder where no benefit from early intervention exists should be avoided. Instead, the child should be left to make his or her own informed decision as an adult.
Identifying a disease gene in families
In families with a genetic disease for which the causativegene is unknown, single nucleotide polymorphisms (SNPs) can be used to track or ‘map’ disease genes using a technique called genome-wide linkage analysis. Microarray-based techniques allow more than
500 000 SNPs to be typed in a single experiment, and
by comparison of the segregation of patterns of contiguous
SNPs (called haplotypes) in affected and unaffected
individuals, the ‘locus’ of DNA where the responsible gene resides can be identified. The confidence of association (‘linkage’) with the disease in question is influenced by the number of subjects studied, the strength of the effect of the gene on the disease, and the closeness of the SNP to the gene in question.
The confidence can be expressed as a LoD
(logarithm of the odds) score, which is −log10 of the
probability (p value) of linkage; by convention, a LoD
score of more than 3 (p < 0.001) is taken to be statistically
significant. Once a locus has been identified, more
detailed mapping within the locus can be undertaken
and the relevant mutation confirmed by sequencing the
relevant gene. Over recent years, next-generation
sequencing of every exon in the genome (exome
sequencing) has been used as an alternative to linkage
analysis in identifying disease-causing mutations in families.
Typically affected individuals within the family are sequenced and the results compared with unaffected family members and controls from the general population. For a fully penetrant disorder, the disease-causing mutation will be present in affected individuals and not present in unaffected family members or unrelated controls.
Genetic investigation in populations
Genetic screening may be applied to whole populations.The criteria for the use of population screening are well
established; they depend on the incidence of specific
conditions in individual populations and on whether
an intervention is available to ameliorate the effects of
the disease. In the UK, examples include screening for
phenylketonuria and cystic fibrosis in the newborn, and
prenatal screening for neural tube defects and Down’s
syndrome in pregnant women .
Screening for carriers of haemoglobinopathies and Tay–Sachs disease is also carried out in some countries where the incidence of these conditions may be high enough to merit screening the entire population .
Predictive genetic testing
In the absence of symptoms or signs of disease in an
individual at risk, a genetic test can be used to determine
whether that individual carries the disease-causing
mutation. This is known as pre-symptomatic or predictive
genetic testing. Predictive tests are usually carried
out for adult-onset disorders such as familial cancer syndromes and neurodegenerative disorders such as Huntington’s disease , or when a positive result in
children will affect screening and management, such as
in familial polyposis coli .
However, many complicated ethical issues arise with testing of children and such tests should only be carried out by clinicians experienced in their use.
Whilst a negative predictive test is clearly a favourable
outcome for the individual concerned, a positive
test may have significant negative consequences. These
should have been explained fully in the counselling
process (see below), and include employment discrimination
and psychological effects.
Providing this is done, current evidence suggests that serious psychological sequelae are uncommon.

Predictive testing for Huntington’s disease
PRESENTING PROBLEMS IN GENETIC DISEASE
There are many thousands of known single-gene diseases.Individually these are rare, but collectively they
are relatively common.
This diversity makes clinical genetics a fascinating clinical specialty but it does mean that it is difficult, if not impossible, for any individual clinician to memorise the features associated with all these disorders.
It is therefore important to have an awareness of the existence of genetic diseases and some general rules or ‘triggers’ in mind.
Although single-gene disorders can present at any age (Box) and affect any tissue or organ system, they share some general characteristics:
• positive family history
• early age of onset
• multisystem involvement
• no obvious non-genetic explanation.
It is important to recognise any unusual clinical presentation
and to consider genetic disease in the context
of the clinical findings and the family history. Publicly
accessible online catalogues of Mendelian diseases can
be useful sources of potential diagnoses.

Genetic disease and counselling in old age
MAJOR CATEGORIES OF GENETIC DISEASEIt is clearly impossible to discuss all Mendelian disease
in this chapter, as there are many thousands of single -gene
disorders. However, the major categories of genetic
disease that are commonly encountered by clinical
geneticists in adult practice are discussed below.
Inborn errors of metabolism
Inborn errors of metabolism (IEM) are caused by mutations
that disrupt the normal function of a biochemical pathway. A good example is the glycogen storage diseases , which are caused by mutations in various genes involved in regulating glucose metabolism. Most IEM are due to autosomal or X-linked recessive loss-of-function mutations in genes encoding specific enzymes or enzymatic co-factors.
Many hundreds of different IEM have been identified and these disorders have contributed a great deal to our understanding of human biochemistry.
Most IEM are very rare and some are restricted to paediatric practice; however, a growing number may now present during adult life.
In the porphyrias, the intoxication is caused by a
build-up in the metabolites involved in haem synthesis.The diagnosis of these disorders requires specialist biochemical analysis of blood and/or urine. In some disorders, treatment relies on removal of the toxic substance using haemodialysis or chemical conjugation, or prevention of further accumulation by restricting intake of the precursors, such as total protein restriction in urea cycle
disorders and avoidance of branched-chain amino-acid
intake in maple syrup urine disease. In other disorders,
such as the porphyrias, treatment is based on avoiding
precipitating factors and supportive care.
Mitochondrial disorders
Disorders of energy production are the most common
type of IEM presenting in adult life, and some of these
disorders have been mentioned in the section on mitochondrial function . The tissues that are most commonly affected in this group of disorders are those with the highest metabolic energy requirements, such as muscle, heart, retina and brain. Therapy in this group of disorders is based on giving antioxidants and co-factors, such as vitamin C and ubiquinone, that can improve the function of the respiratory chain.
Storage disorders
Storage disorders involve enzyme deficiency in lysosomal degradation pathways. The clinical consequences depend on the specific enzyme involved. For example, Fabry disease, an X-linked recessive deficiency of α-galactosidase A, results in abdominal pain, episodicdiarrhoea, renal failure and angiokeratoma. Niemann–
Pick disease type C is caused by autosomal recessive
loss-of-function mutations in either the NPC1 or NPC2
gene. These result in lysosomal cholesterol accumulation,
causing hepatosplenomegaly, dysphagia, loss of
speech, very early dementia, spasticity and dystonia. An
increasing number of storage disorders are treatable
with enzyme replacement or substrate depletion therapies,making awareness and diagnosis more important.
Neurological disorders
Progressive neurological deterioration is one of the mostcommon presentations of adult genetic disease. These
diseases are mostly autosomal dominant and can be
grouped into specific neurological syndromes and earlyonset forms of well-known, non-Mendelian clinical
entities. In the latter group, the best examples would
be early-onset familial forms of dementia, Parkinson’s
disease and motor neuron disease. The triplet repeat disorders cause an interesting group of syndromes and
have specific features that are dealt with below.
Huntington’s disease (HD)
Is the paradigm of triplet repeat disorders. This condition can present with a movement disorder, weight loss or psychiatric symptoms (depression, addiction, psychosis, dementia), or with a combination of all three. The disease is the result of a [CAG]n triplet repeat expansion mutation in the HD gene on chromosome 4. Since CAG is a codon for
glutamine and this mutation is positioned in the ORF,
this results in an expansion of a polyglutamine tract in
the protein. The mutation probably leads to gain of function, as deletions of the gene do not cause HD. The
function of the protein encoded by the HD gene is not
fully understood, but expansion of the repeat to above
the normal range of 3–35 results in neurological disease.
In general, the severity of disease and age at onset are
related to the repeat length. In HD, atrophy of thecaudate nuclei and the putamen is obvious on magnetic
resonance imaging (MRI) of the brain, and in later stages
cerebral atrophy is also apparent.
There is currently no therapy that will alter the progression of the disease, which will often be the cause of the patient’s death.
Within families there is a tendency for disease severity
to increase and age at onset to fall due to further expansion of the repeat, a phenomenon known as anticipation.
The mutation is more likely to expand through the male
germ line than through female meiosis.
Other triplet repeat disorders
Other progressive neurological disorders caused bytriplet repeat expansion mutations in different genes
include several forms of autosomal dominant spinocerebellar ataxias, dentatorubral-pallidoluysian atrophy (DRPLA), Machado–Joseph disease and Kennedy
disease. These polyglutamine disorders all show intracellular inclusions in affected cells. It is thought that this
accumulation may, in itself, be deleterious and is the
result of defective protein degradation. Myotonic dystrophy and Friedreich’s ataxia are also triplet repeat
expansion disorders but the pathogenetic mechanism
associated with these diseases is different, as these repeats do not lie within the coding regions of the affected genes.
Connective tissue disorders
Mutations in different types of collagen, fibrillin and
elastin make up the majority of connective tissue disorders.
The clinical features of these disorders vary, depending on the structural function and tissue distribution of the protein that is mutated. For example, autosomal dominant loss-of-function mutations in the gene encoding elastin cause either supravalvular aortic stenosis, cutis laxa or a combination of both conditions.The most commonly involved systems are:
• skin (increased or decreased elasticity, poor wound
healing)
• eyes (myopia, lens dislocation)
• blood vessels (vascular fragility)
• bones (osteoporosis, skeletal dysplasia)
• joints (hypermobility, dislocation, arthropathy).
Learning disability, dysmorphism and malformations
Congenital global cognitive impairment (also calledmental handicap or learning disability) affects about 3%
of the population. It is commonly divided into broad
categories of mild to moderate (IQ 50–70), moderate to
severe (IQ 20–50), and severe to profound (IQ < 20).
There are important ‘environmental’ causes of global
cognitive impairment, including:
• teratogen exposure during pregnancy (alcohol,
anticonvulsants)
• congenital infections (cytomegalovirus, rubella,
toxoplasmosis, syphilis)
• the sequelae of prematurity (intraventricular
haemorrhage)
• birth injury (hypoxic ischaemic encephalopathy).
Genetic disorders contribute very significantly to the
aetiology of global cognitive impairment. Given the
complexity of brain development, it is not surprising
that global cognitive impairment shows extreme locus
heterogeneity.
The three most important groups of disorder are reviewed below.
Chromosome disorders
Any significant gain or loss of autosomal chromosomalmaterial (known as aneuploidy) usually results in learning disability and other phenotypic abnormalities. Down’s syndrome is the most frequently found and best known of these disorders, and is caused by an increased dosage of genes on chromosome 21. Most cases of Down’s syndrome are due to a numerical chromosome abnormality with trisomy of chromosome 21, e.g. 47,XX,+21 or 47,XY,+21.
The clinical features are:
• globally delayed development• characteristic facial appearance
• a significant risk of specific malformations
(atrioventricular septal defect, duodenal atresia)
• a predisposition to several late-onset disorders,
including hypothyroidism, acute leukaemias and
Alzheimer’s disease.
Recent surveys have shown that DNA microarray analysis can identify causative structural chromosome abnormalities in 10–25% of cases of significant learning disability. These deletions and duplications are mostly de novo and unique. An interest group of recurrent deletions and duplication caused by non-allelic homologous recombination events has been mentioned above. These result in specific microdeletion or microduplication syndromes, such as:
• velocardiofacial syndrome due to deletion of 22q11.2 (learning disability, malformations of the cardiac outflow tract, cleft palate, distinctive facial appearance and immune disorders)
• Williams’ syndrome due to deletion of 7q11.23 (learning disability, supravalvular aortic stenosis and mild cutis laxa as a result of deletion of the elastin gene, distinctive facial appearance and
over-friendly, chatty personality).
Dysmorphic syndromes
There are several thousand different dysmorphic syndromes; all are rare but they are characterised by the occurrence of cognitive impairment, malformations and
a distinctive facial appearance – or ‘gestalt’ – associated
with various other clinical features. Making the correct
diagnosis is important, as it has profound implications
on immediate patient management, detection of future
complications and assessment of recurrence risks in the
family.
Clinical examination remains the mainstay of diagnosis and the patient often needs to be evaluated by a clinician who specialises in the diagnosis of these syndromes.
The differential diagnosis in dysmorphic syndromes
is often very wide and this has resulted incomputer-aided diagnosis becoming an established clinical
tool. Dysmorphology databases such as POSSUM
and LMD have been established that are curated catalogues of the many thousands of known syndrome entities; they can be searched to identify possible explanations of unusual combinations of clinical features. The clinical diagnosis may then be confirmed by specific genetic investigations, as the genetic basis of a wide range of dysmorphic syndromes has been identified.
Familial cancer syndromes
Most cancers are not inherited but occur as the result ofan accumulation of somatic mutations, as discussed previously. However, it has been recognised
for many decades that some families are prone to one or
more specific types of cancer. Affected individuals tend
to present with tumours at an early age and are more
likely to have multiple primary foci of carcinogenesis.
Retinoblastoma
Patients with autosomal dominant familial retinoblastoma
have an inherited mutation in one copy of the RB gene, which is a tumour suppressor.
This strongly predisposes individuals to the formation of retinoblastoma in one or both eyes. It is possible for more than one primary tumour to form in the same eye and for retinoblastoma to occur in the pineal gland. From a clinical
perspective, it is important to screen the eyes and pineal
gland of such individuals regularly so that tumours can
be treated early and sight preserved.
This gene is widely expressed and it is not clear why the retina is the main site of oncogenesis in this syndrome. An increased incidence of osteogenic sarcoma is also seen in affected individuals.
Familial adenomatous polyposis coli
Familial adenomatous polyposis coli (FAP) is an autosomaldominant condition due to inactivation mutations
in the FAP tumour suppressor gene on 5q. The gene
product is thought to modulate a specific signalling
cascade (Wnt signalling) that regulates cell proliferation.
Mutation carriers usually develop many thousands of
intestinal polyps in their second and third decades and
have a very high risk of malignant change in the colon.
Prophylactic colectomy in the third decade is necessary
in most cases. Regular screening for polyps in the upper
gastrointestinal tract is also recommended.
Hereditary non-polyposis colorectal cancer
Hereditary non-polyposis colorectal cancer (HNPCC) isan autosomal dominant disorder that presents with
early-onset familial colon cancer, particularly affecting
the proximal colon. Other cancers, such as endometrial
cancer, are often observed in affected families. This disorder shows marked locus heterogeneity, as mutations
can occur in several different genes encoding proteins
involved in DNA mismatch repair.
Familial breast cancer
Familial breast cancer is an autosomal dominant disorder
that is most often due to mutations in genes encoding
either BRCA1 or BRCA2. Both of these proteins are
involved in DNA repair. Individuals who carry a BRCA1
or BRCA2 mutation are at high risk of early-onset breast
and ovarian tumours, and require regular screening for
both of these conditions. Because of the very high risk
of cancer, many women who carry these mutations elect
to have prophylactic bilateral mastectomy and oophorectomy in the absence of a detectable tumour.
Xeroderma pigmentosum
Xeroderma pigmentosum (XP) is the name given to agroup of rare disorders in which there are autosomal
recessive defects in DNA repair genes that deal primarily with the effects of non-ionising radiation. The
skin is particularly involved, and affected patients
develop skin cancers with increased frequency.
GENETIC COUNSELLING
Genetic counselling provides information about themedical and family implications of a specific disease in
a clear and non-directive manner. Such counselling aims
to help individuals make informed decisions about planning
a family, taking part in screening programmes and
accepting prophylactic therapies. Genetic counselling
may be provided by a medical geneticist, a specialist
nurse, or a clinician with particular skills in this area,
such as an obstetrician or paediatrician (Box). Perception
of genetic risks clearly depends on perceived
hazard. For example, a 5% (or 1 : 20) risk of genetic
disease may be perceived as low if the disease is treatable, but unacceptably high if not.
Specific problems encountered in genetic counselling
include:
• accurate assessment of genetic risk
• identification of children at risk of genetic disorders
• the increase in genetic risks associated with
consanguinity
• non-paternity as an incidental finding in DNA.
Clinical genetics services
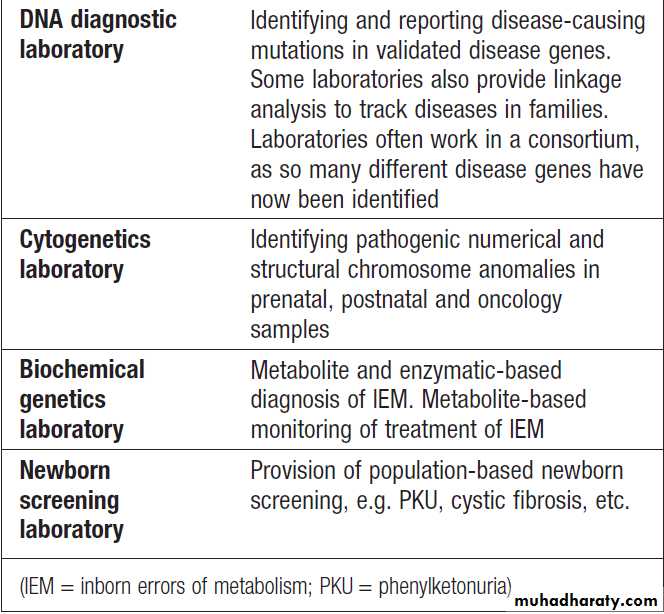

Clinical genetics services
– cont’dGenetic tests are increasingly used for the diagnosis
and prediction of Mendelian disease in a medical
context, and such skills will become increasingly important
for many clinicians.
Genetic risk is often calculated using Bayes’ theorem
which takes prior risk into account to calculate future risk. A simple Bayesian calculation is illustrated here. Consider a woman who is at risk of being a carrier of an X-linked recessive disease. Her grandfather and brother are affected, which makes her mother an obligate gene carrier. Her risk of being a carrier is therefore 50%. However, she has two unaffected sons.
This information can be used to modify her risk. The prior probability that she is a carrier is 1 : 2 and
that she is not a carrier also 1 : 2. The conditional probability that she would have two normal sons if she were a carrier is 1/2 × 1/2, i.e. 1/4. If she were not a carrier, the probability of having normal sons is 1. From this, the joint probability for each outcome can be calculated (the prior risk × the conditional risk): 1/2 × 1/4 (1/8) for being a carrier and 1/2 × 1 (1/2) for not being a carrier. The final risk, or relative probability, for each outcome can then be obtained by dividing the joint probability for that outcome by the sum of the joint probabilities. The probability that she is a carrier is therefore 1/8(1/8 + 1/2) = 1/5 (20%).
GENETICS OF COMMON DISEASES
Many common disorders, such as diabetes, atherosclerosis,hypertension, cancer, osteoarthritis, inflammatory
bowel disease and osteoporosis, have an important
genetic component but are not caused by a single mutation.
Techniques are now available both to measure the
contribution and to identify genes with significant
effects. This means that the result of genetic testing is
beginning to have an impact on diagnosis, prognosis
and therapy for common diseases, and this trend is likely to expand significantly in the years to come. Some of the most useful approaches to clinical interpretation of the genetic aspects of common disorders are outlined below.
Measuring the genetic contribution to complex disease
Genetic contributions to complex disease can be detected
and quantified by twin studies and/or by analysing
familial clustering. Twin studies use the difference in
disease concordance between monozygotic (MZ) and
dizygotic (DZ) twins to calculate genetic contribution.
MZ twins are genetically identical, whereas DZ twins,
like all siblings, are identical for only about 50% of their
genetic variation. However, both MZ and DZ twins
share an almost identical intrauterine environment and
similar postnatal environment.
Thus, any evidence of a higher concordance of the disease in MZ compared to DZ twins is assumed to be evidence of genetic contribution.
Many common diseases and quantitative traits,
such as height, weight, blood pressure and bone mineral
density, show higher concordance rates in MZ twins
compared to DZ twins. Genetic contributions to common
diseases can also be assessed by studying the incidence
of the disease in first-degree relatives of affected individuals, as compared with the general population
(Fig. 3.15). The difference in incidence is used to calculate
a disease risk, which is measured by the λs value.

Risk to siblings of affected patients for
common polygenic diseases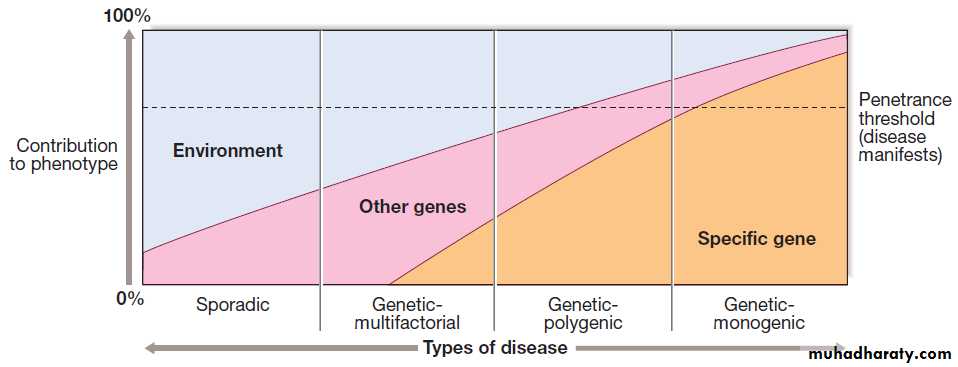
The spectrum of genetic disease:
how the genotype influences the phenotype.A particular characteristic or disease in an individual
may be due to a specific genetic abnormality (monogenic disease) or may reflect several predisposing genes (polygenic disease).
In each case, environmental factors may further influence the phenotype; in their absence, genetic factors alone may be insufficient to allow the disease to develop, resulting in non-penetrance or reduced penetrance.
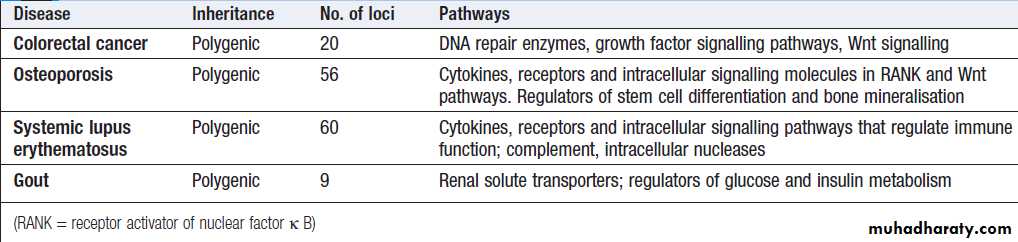
Polymorphisms that predispose to common diseases
RESEARCH FRONTIERS IN MOLECULAR MEDICINEGene therapy
Replacing or repairing mutated genes (gene therapy) is
very difficult in humans. Retroviral-mediated ex vivo
replacement of the defective gene in bone marrow cells
for the treatment of severe combined immune deficiency
syndrome has been partially successful. There
have been two major problems with the clinical trials of
virally delivered gene therapy conducted to date:
• The random integration of the retroviral DNA
(which contains the replacement gene) into the
genome has caused leukaemia in some treated
children via activation of proto-oncogenes.
• A severe immune response to the viral vector may
be induced. It has not yet been possible to use
non-viral means to introduce sufficient numbers of
copies of replacement genes to produce significant
biological effects.
Other therapies for genetic disease include PTC124,
a compound that can ‘force’ cells to read through a
mutation that results in a premature termination codon
in an ORF with the aim of producing a near-normal
protein product.
This therapeutic approach could be applied to any genetic disease caused by nonsense mutations.
Induced pluripotent stem cells and regenerative medicine
Adult stem cell therapy has been in wide use for decadesin the form of haematopoietic stem cell transplantation.
The identification of adult stem cells for other tissues,
coupled with the ability to purify and maintain such
cells in vitro, now offers exciting therapeutic potential
for other diseases. Many different adult cell types can be
transdifferentiated to form cells termed induced pluripotent
stem cells (iPS cells) with almost all the characteristics
of embryonic stem cells.
In mammals, iPS cells can be used to regenerate various tissues such as the heart and brain. They have great potential both to develop tissue models of human disease and for regenerative medicine. In mammalian model species, such cells can be taken and used to regenerate differentiated tissue cells, such as in heart and brain.
Pathway medicine
The ability to manipulate pathways that have beenaltered in genetic disease has tremendous therapeutic
potential for Mendelian disease, but a firm understanding
of both disease pathogenesis and drug action at a
biochemical level is required. An exciting example of
this has been the discovery that the vascular pathology
associated with Marfan’s syndrome is due to the defective
fibrillin molecules causing up-regulation of transforming
growth factor (TGF)-β signalling in the vessel wall. Losartan is an antihypertensive ,angiotensin II receptor antagonist. However, it also acts as a partial antagonist of TGF-β signalling and is effective in preventing aortic dilatation in a mousemodel of Marfan’s syndrome, showing promising effects in early human clinical trials.